[1] 2.594241e-146Inference: frequentist vs. Bayesian
Day 5
The \(H_0\) Sampling Distribution
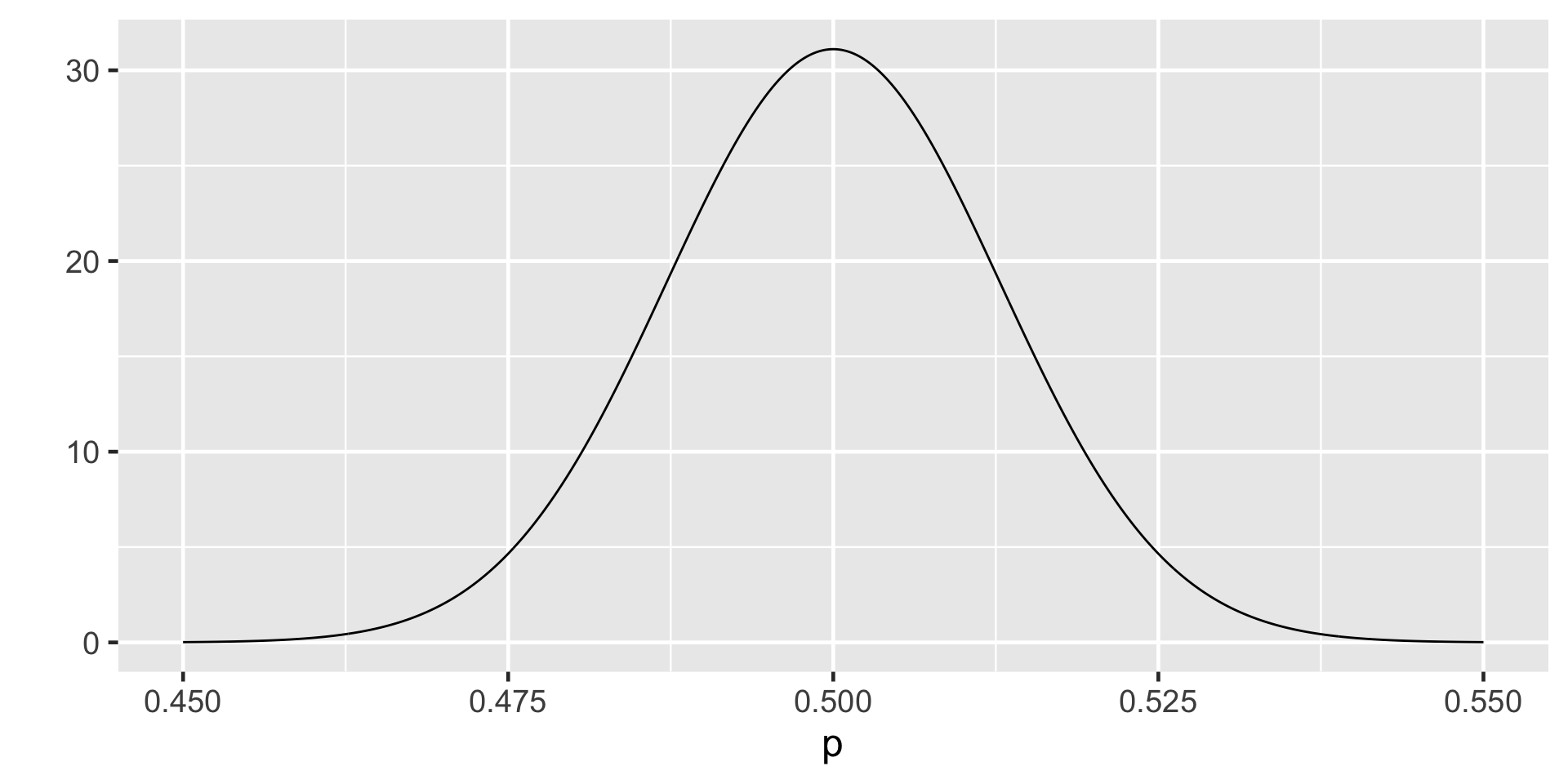
Sampling Distribution
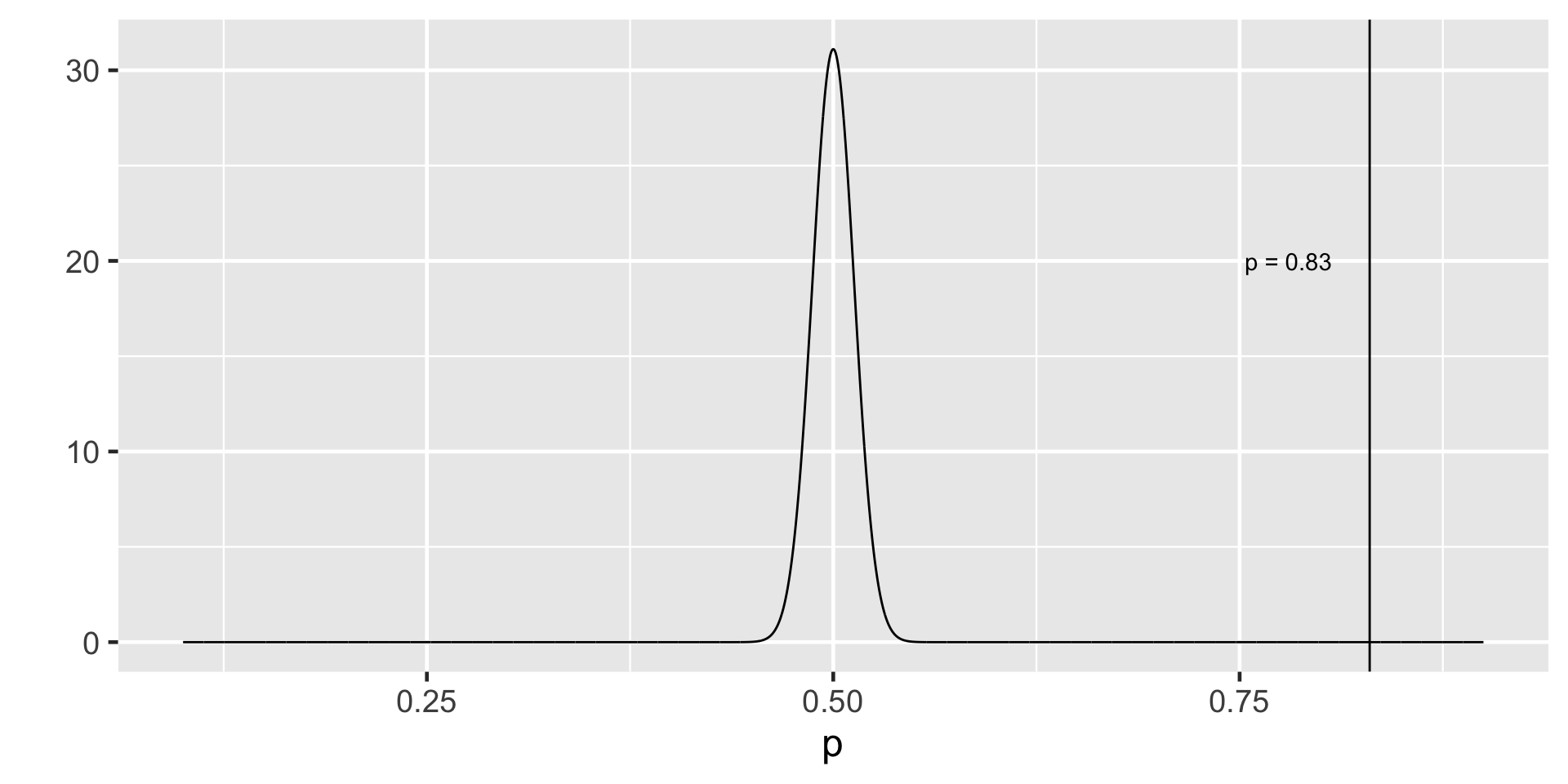
Remembering CLT
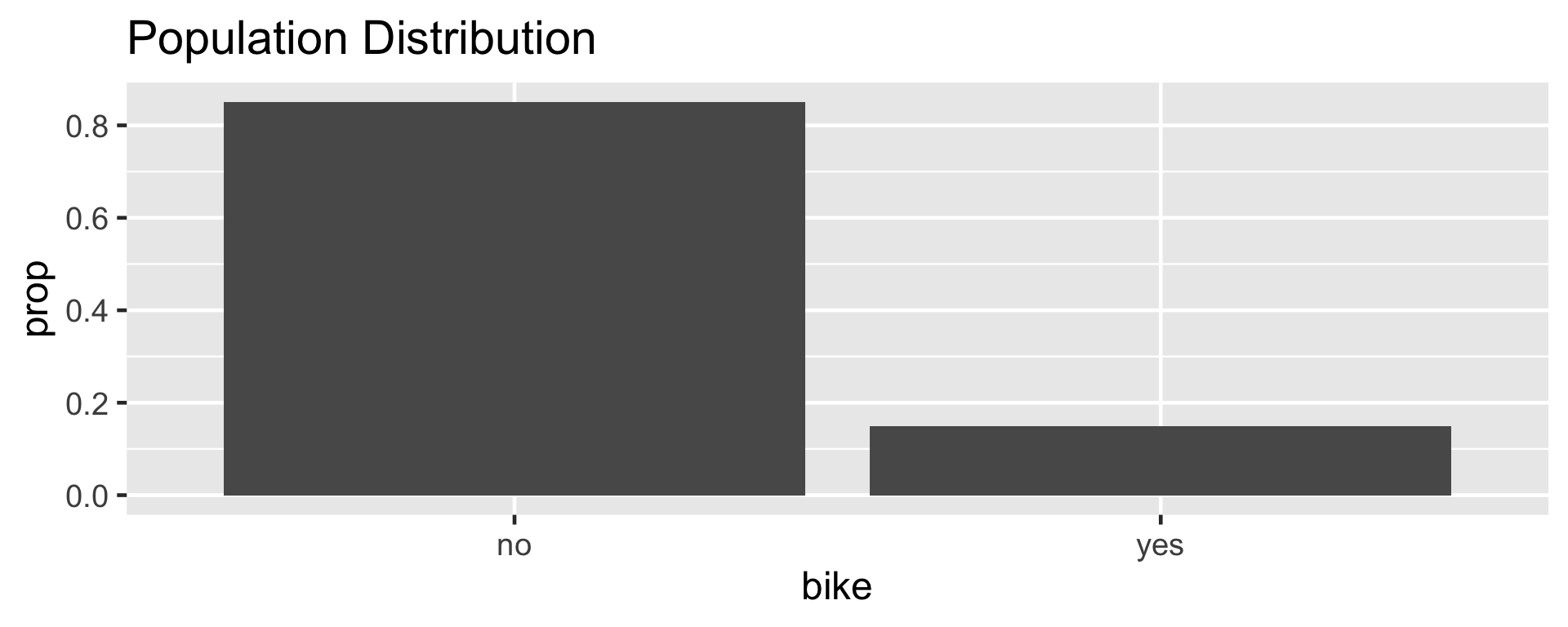
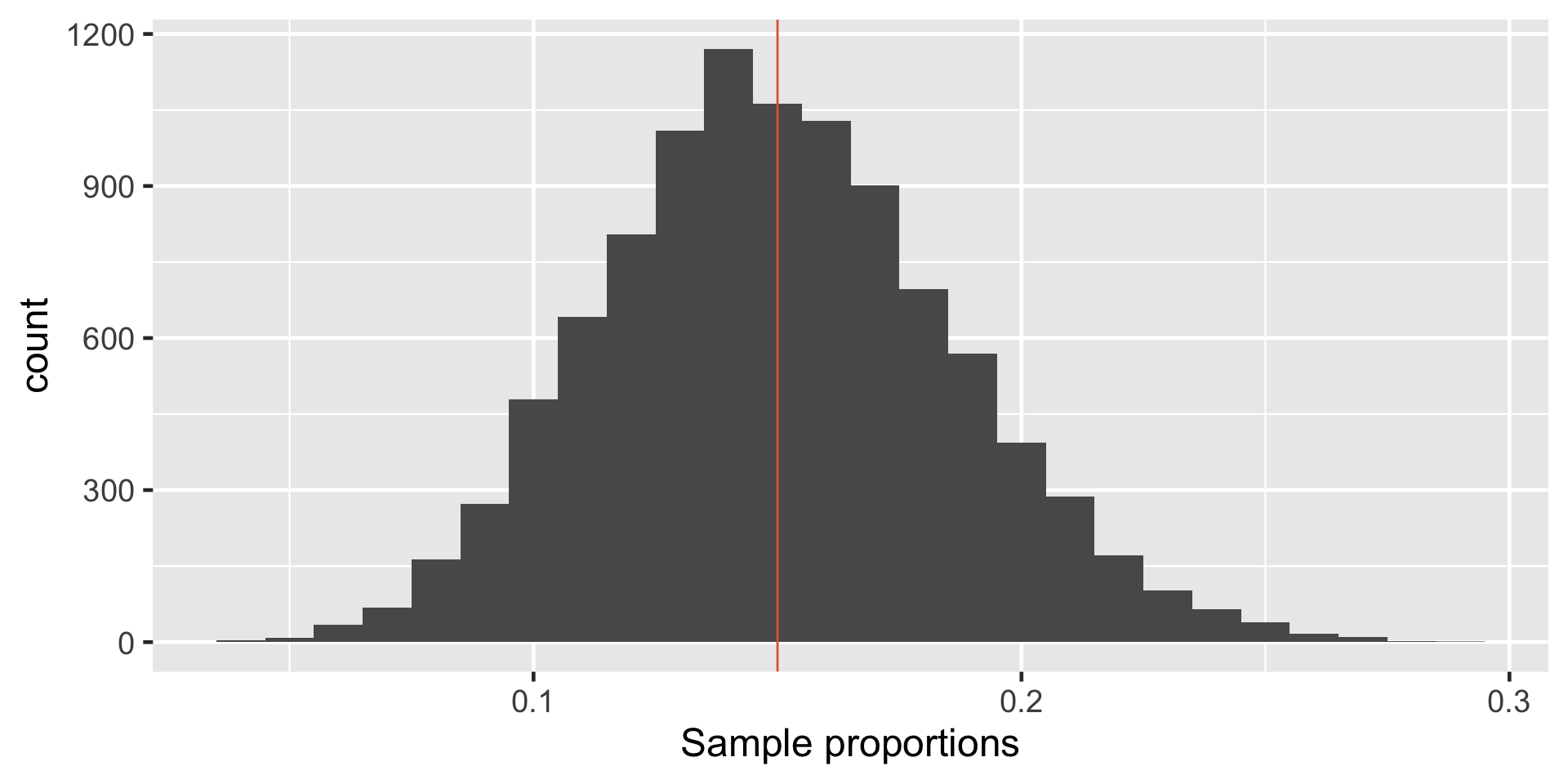
Let \(\pi\) represent the proportion of bike owners on campus then \(\pi =\) 0.15.
Getting to sampling distribution of single proportion
\(p_1\) - Proportion of first sample (n = 100)
[1] 0.17\(p_2\) -Proportion of second sample (n = 100)
[1] 0.12\(p_3\) -Proportion of third sample (n = 100)
[1] 0.14Sampling Distribution of Single Proportion
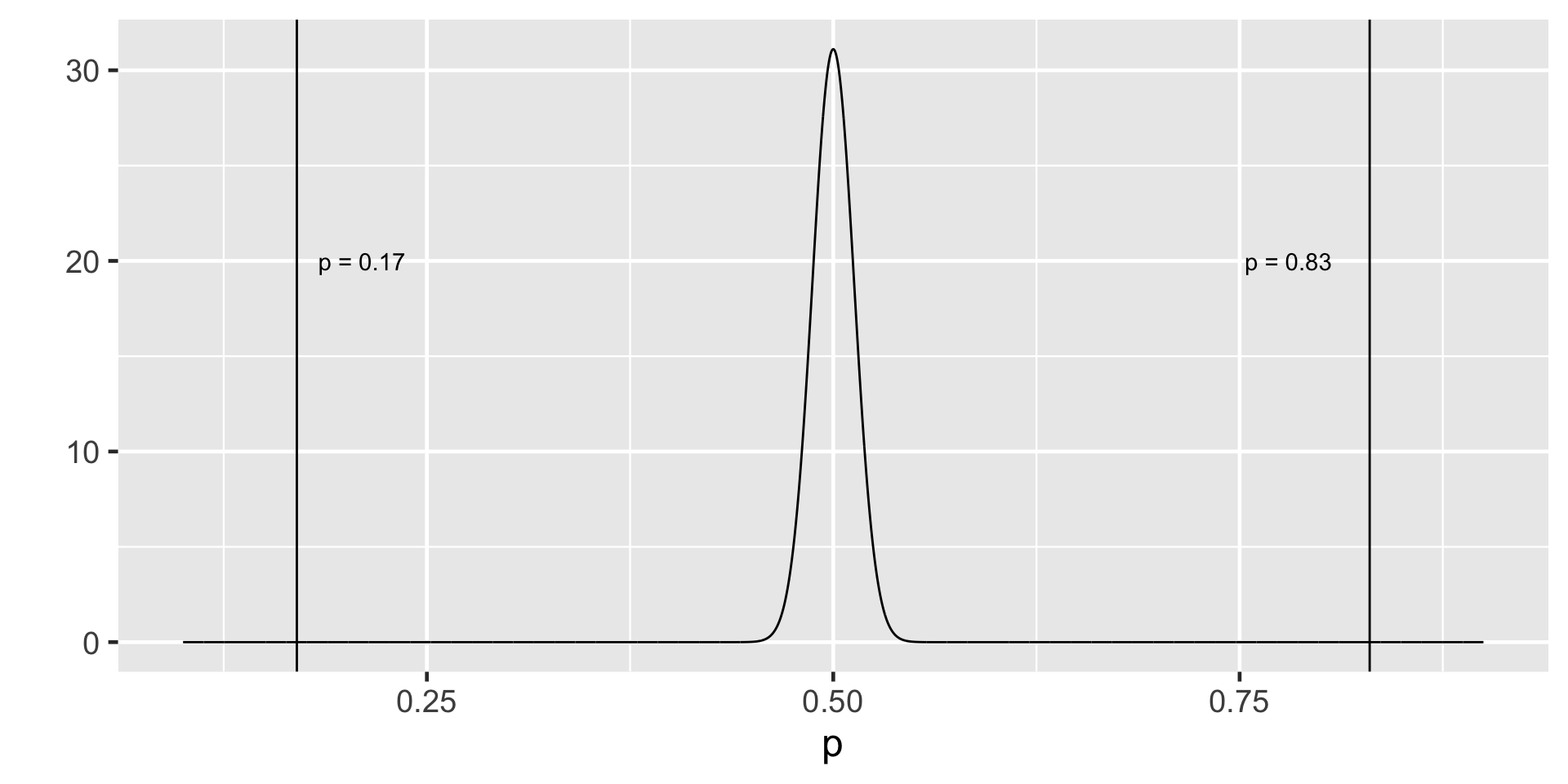
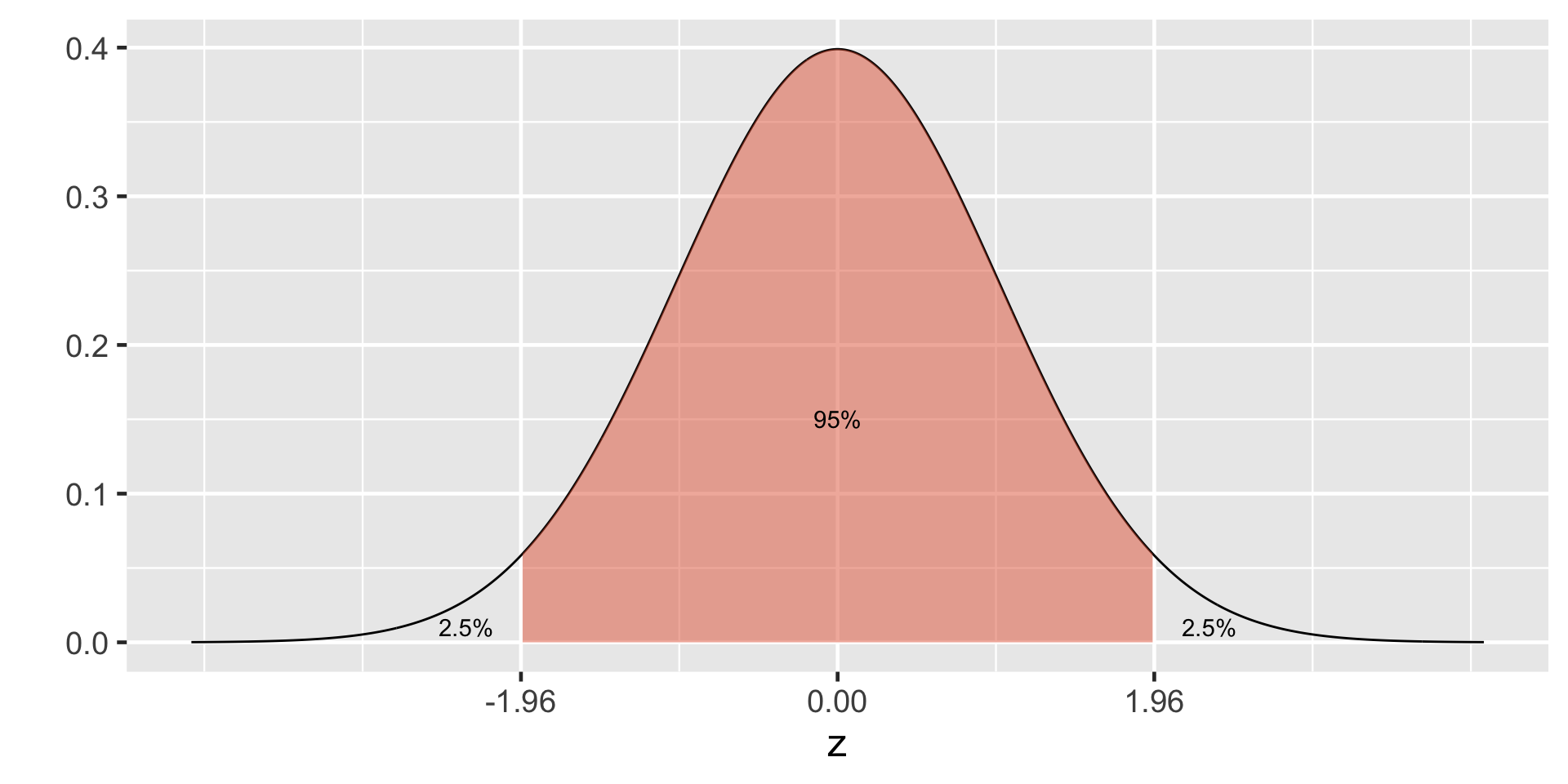
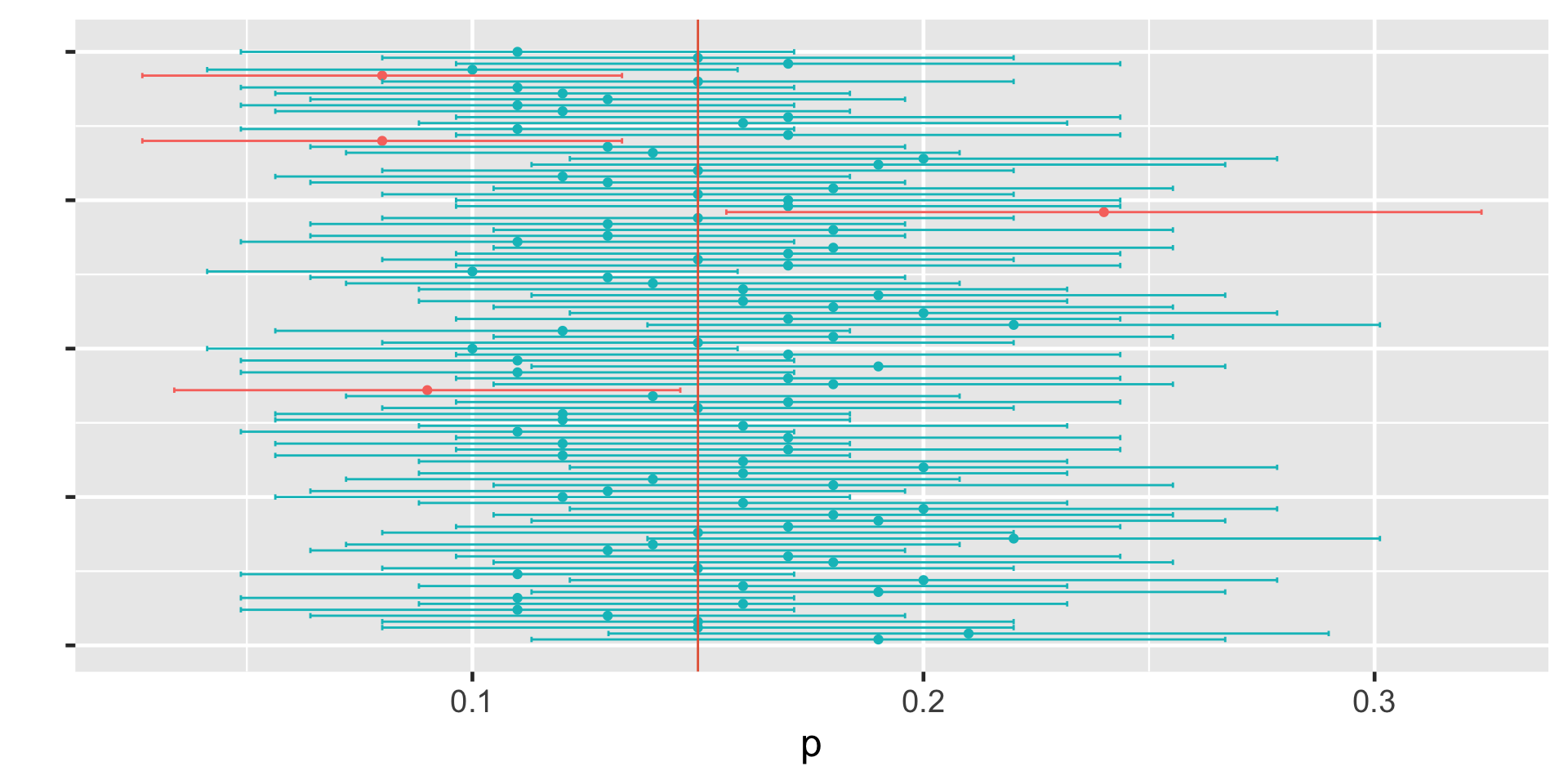
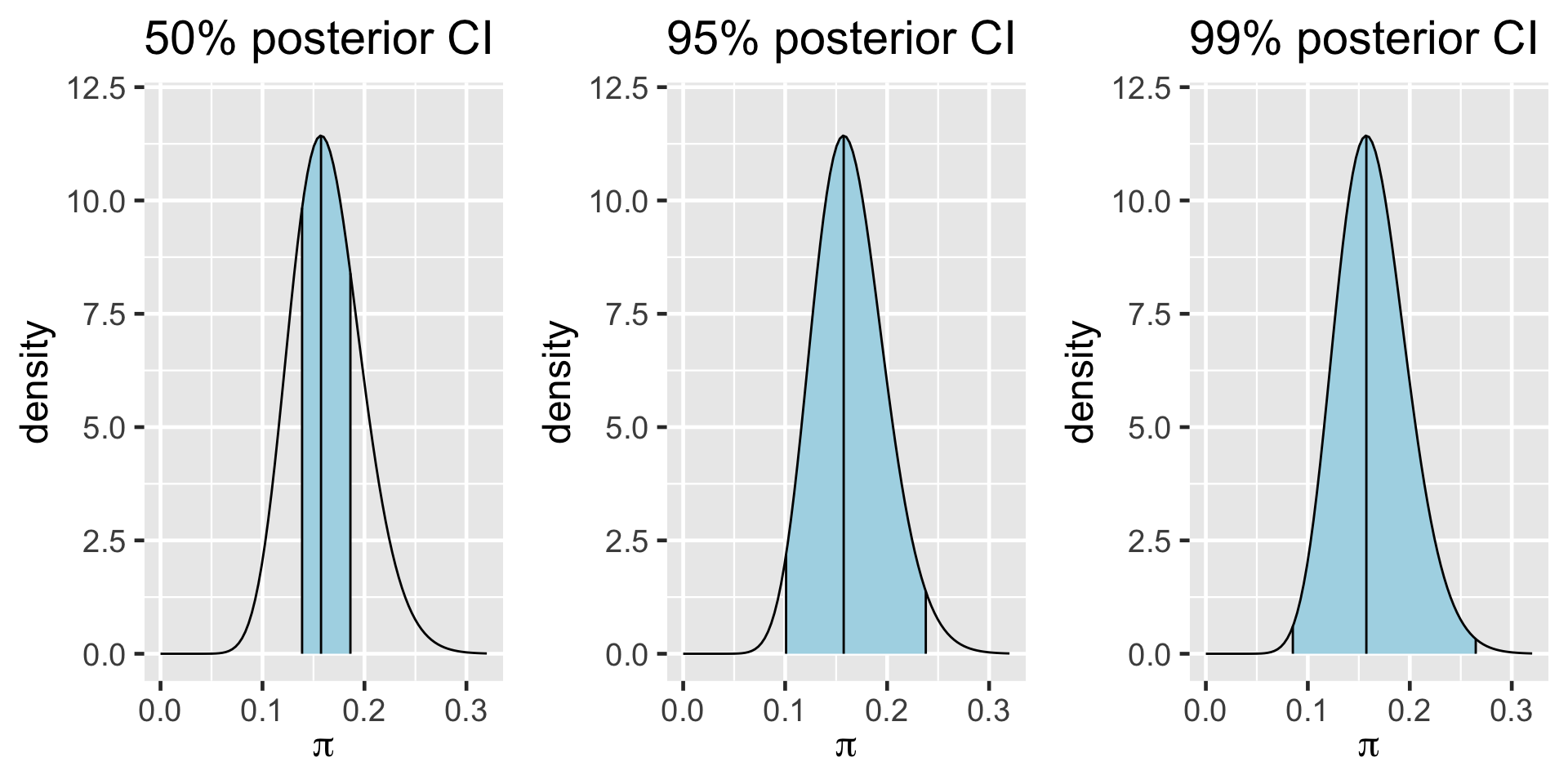
95% of the data falls within 1.96 standard deviations in the normal distribution.
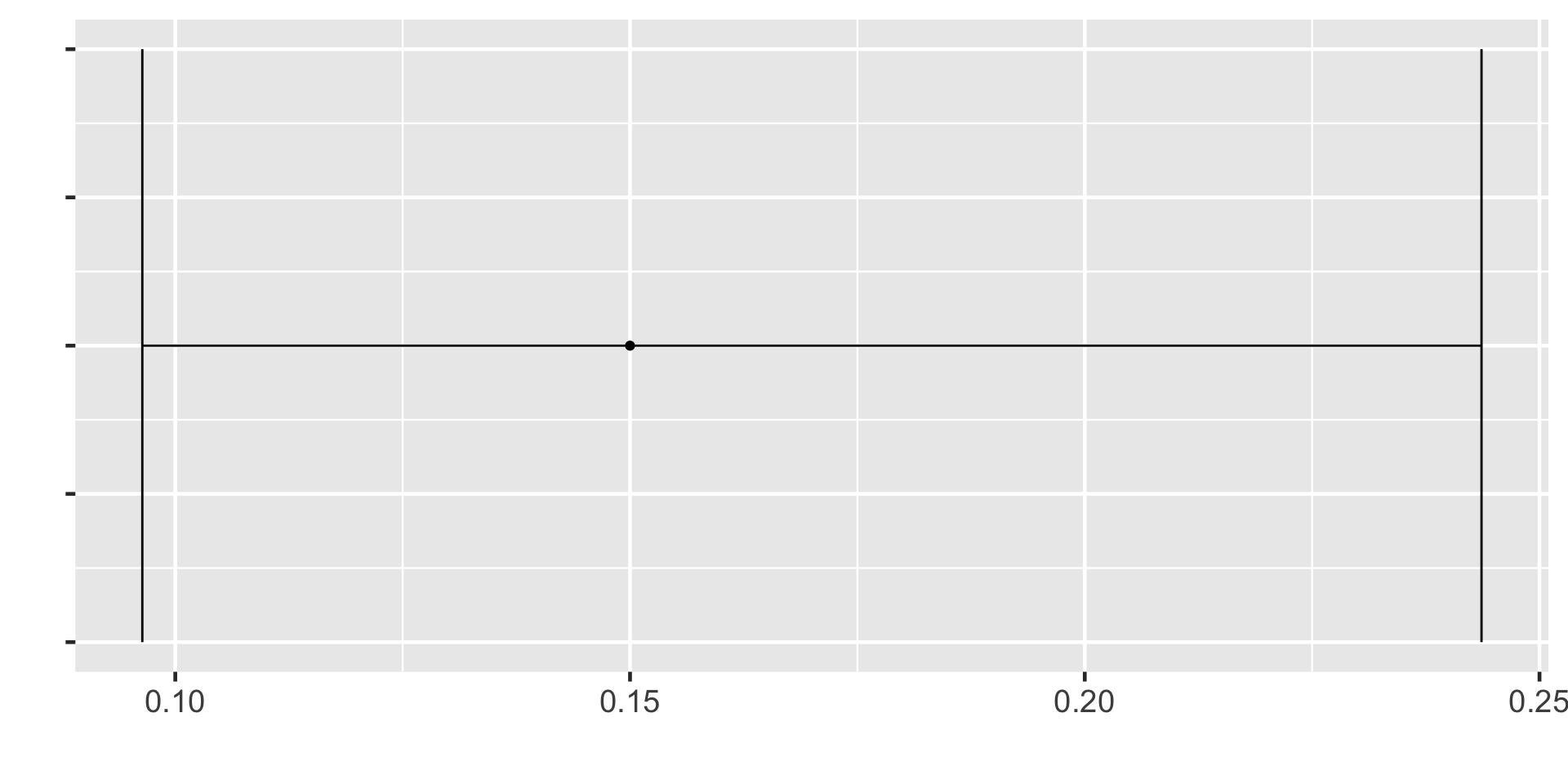
95% CI for the first sample
95%CI = (0.09637597, 0.243624)
We are 95% confident that the true population proportion of bike owners is in this confidence interval.
class: middle center
95%CI = (0.09637597, 0.243624)
Understanding Confidence Intervals
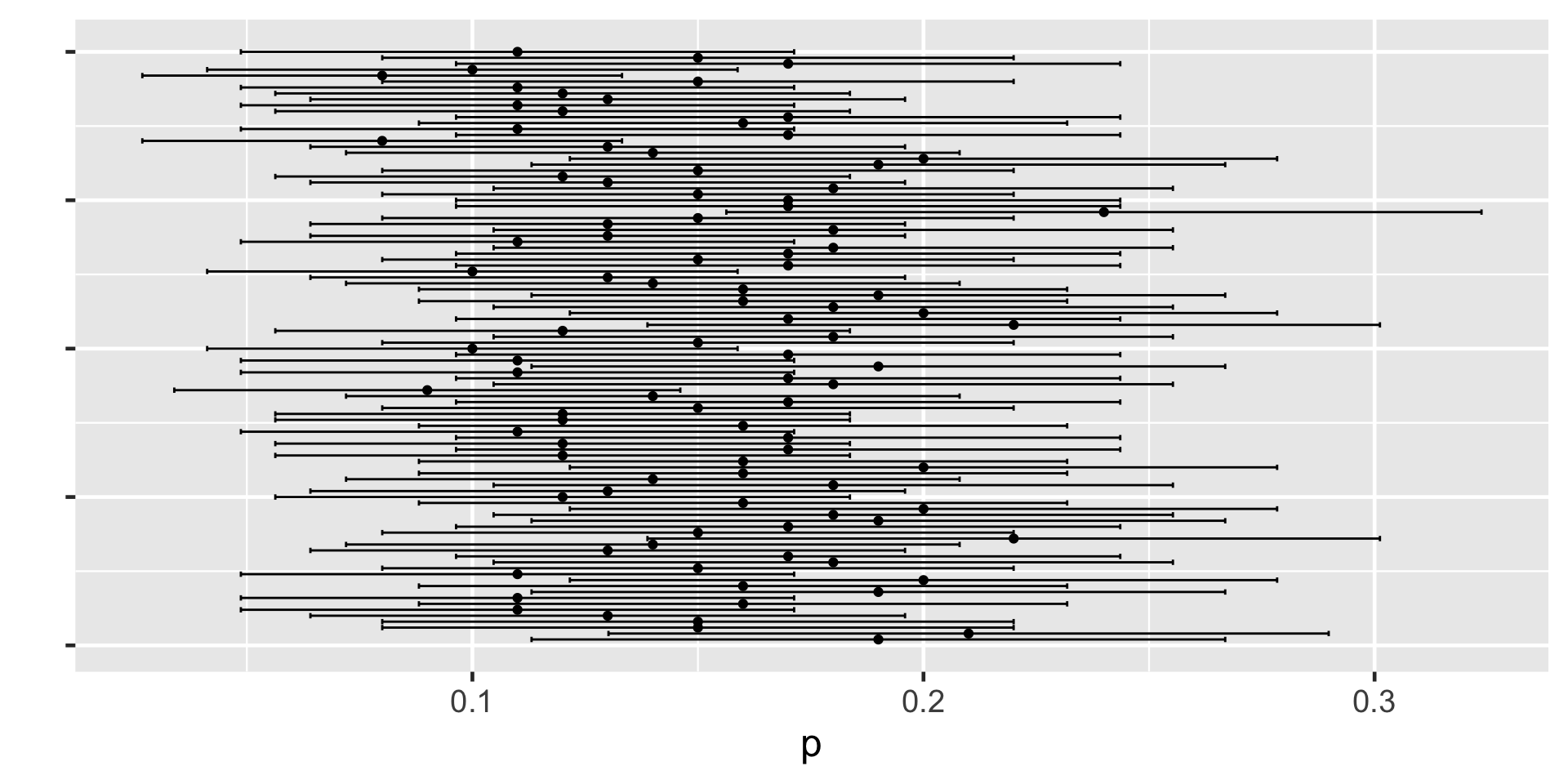
Understanding Confidence Intervals
SAMPLING FOR MODEL '40889b2266edb1362fe73358abd137b3' NOW (CHAIN 1).
Chain 1:
Chain 1: Gradient evaluation took 2.1e-05 seconds
Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 0.21 seconds.
Chain 1: Adjust your expectations accordingly!
Chain 1:
Chain 1:
Chain 1: Iteration: 1 / 10000 [ 0%] (Warmup)
Chain 1: Iteration: 1000 / 10000 [ 10%] (Warmup)
Chain 1: Iteration: 2000 / 10000 [ 20%] (Warmup)
Chain 1: Iteration: 3000 / 10000 [ 30%] (Warmup)
Chain 1: Iteration: 4000 / 10000 [ 40%] (Warmup)
Chain 1: Iteration: 5000 / 10000 [ 50%] (Warmup)
Chain 1: Iteration: 5001 / 10000 [ 50%] (Sampling)
Chain 1: Iteration: 6000 / 10000 [ 60%] (Sampling)
Chain 1: Iteration: 7000 / 10000 [ 70%] (Sampling)
Chain 1: Iteration: 8000 / 10000 [ 80%] (Sampling)
Chain 1: Iteration: 9000 / 10000 [ 90%] (Sampling)
Chain 1: Iteration: 10000 / 10000 [100%] (Sampling)
Chain 1:
Chain 1: Elapsed Time: 0.017894 seconds (Warm-up)
Chain 1: 0.018165 seconds (Sampling)
Chain 1: 0.036059 seconds (Total)
Chain 1:
SAMPLING FOR MODEL '40889b2266edb1362fe73358abd137b3' NOW (CHAIN 2).
Chain 2:
Chain 2: Gradient evaluation took 1e-06 seconds
Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 0.01 seconds.
Chain 2: Adjust your expectations accordingly!
Chain 2:
Chain 2:
Chain 2: Iteration: 1 / 10000 [ 0%] (Warmup)
Chain 2: Iteration: 1000 / 10000 [ 10%] (Warmup)
Chain 2: Iteration: 2000 / 10000 [ 20%] (Warmup)
Chain 2: Iteration: 3000 / 10000 [ 30%] (Warmup)
Chain 2: Iteration: 4000 / 10000 [ 40%] (Warmup)
Chain 2: Iteration: 5000 / 10000 [ 50%] (Warmup)
Chain 2: Iteration: 5001 / 10000 [ 50%] (Sampling)
Chain 2: Iteration: 6000 / 10000 [ 60%] (Sampling)
Chain 2: Iteration: 7000 / 10000 [ 70%] (Sampling)
Chain 2: Iteration: 8000 / 10000 [ 80%] (Sampling)
Chain 2: Iteration: 9000 / 10000 [ 90%] (Sampling)
Chain 2: Iteration: 10000 / 10000 [100%] (Sampling)
Chain 2:
Chain 2: Elapsed Time: 0.018052 seconds (Warm-up)
Chain 2: 0.019912 seconds (Sampling)
Chain 2: 0.037964 seconds (Total)
Chain 2:
SAMPLING FOR MODEL '40889b2266edb1362fe73358abd137b3' NOW (CHAIN 3).
Chain 3:
Chain 3: Gradient evaluation took 2e-06 seconds
Chain 3: 1000 transitions using 10 leapfrog steps per transition would take 0.02 seconds.
Chain 3: Adjust your expectations accordingly!
Chain 3:
Chain 3:
Chain 3: Iteration: 1 / 10000 [ 0%] (Warmup)
Chain 3: Iteration: 1000 / 10000 [ 10%] (Warmup)
Chain 3: Iteration: 2000 / 10000 [ 20%] (Warmup)
Chain 3: Iteration: 3000 / 10000 [ 30%] (Warmup)
Chain 3: Iteration: 4000 / 10000 [ 40%] (Warmup)
Chain 3: Iteration: 5000 / 10000 [ 50%] (Warmup)
Chain 3: Iteration: 5001 / 10000 [ 50%] (Sampling)
Chain 3: Iteration: 6000 / 10000 [ 60%] (Sampling)
Chain 3: Iteration: 7000 / 10000 [ 70%] (Sampling)
Chain 3: Iteration: 8000 / 10000 [ 80%] (Sampling)
Chain 3: Iteration: 9000 / 10000 [ 90%] (Sampling)
Chain 3: Iteration: 10000 / 10000 [100%] (Sampling)
Chain 3:
Chain 3: Elapsed Time: 0.017845 seconds (Warm-up)
Chain 3: 0.018493 seconds (Sampling)
Chain 3: 0.036338 seconds (Total)
Chain 3:
SAMPLING FOR MODEL '40889b2266edb1362fe73358abd137b3' NOW (CHAIN 4).
Chain 4:
Chain 4: Gradient evaluation took 2e-06 seconds
Chain 4: 1000 transitions using 10 leapfrog steps per transition would take 0.02 seconds.
Chain 4: Adjust your expectations accordingly!
Chain 4:
Chain 4:
Chain 4: Iteration: 1 / 10000 [ 0%] (Warmup)
Chain 4: Iteration: 1000 / 10000 [ 10%] (Warmup)
Chain 4: Iteration: 2000 / 10000 [ 20%] (Warmup)
Chain 4: Iteration: 3000 / 10000 [ 30%] (Warmup)
Chain 4: Iteration: 4000 / 10000 [ 40%] (Warmup)
Chain 4: Iteration: 5000 / 10000 [ 50%] (Warmup)
Chain 4: Iteration: 5001 / 10000 [ 50%] (Sampling)
Chain 4: Iteration: 6000 / 10000 [ 60%] (Sampling)
Chain 4: Iteration: 7000 / 10000 [ 70%] (Sampling)
Chain 4: Iteration: 8000 / 10000 [ 80%] (Sampling)
Chain 4: Iteration: 9000 / 10000 [ 90%] (Sampling)
Chain 4: Iteration: 10000 / 10000 [100%] (Sampling)
Chain 4:
Chain 4: Elapsed Time: 0.018097 seconds (Warm-up)
Chain 4: 0.019304 seconds (Sampling)
Chain 4: 0.037401 seconds (Total)
Chain 4: 
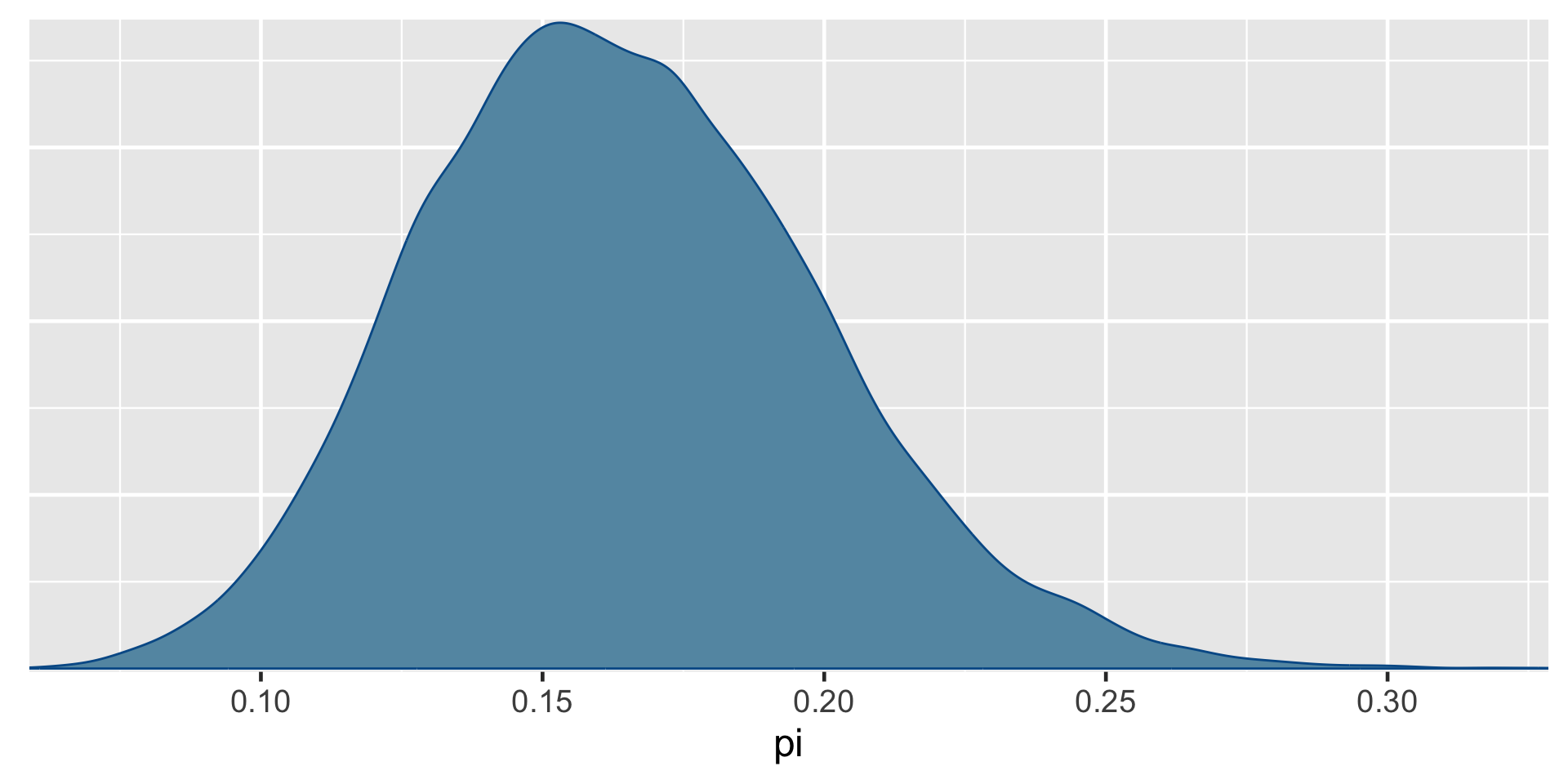
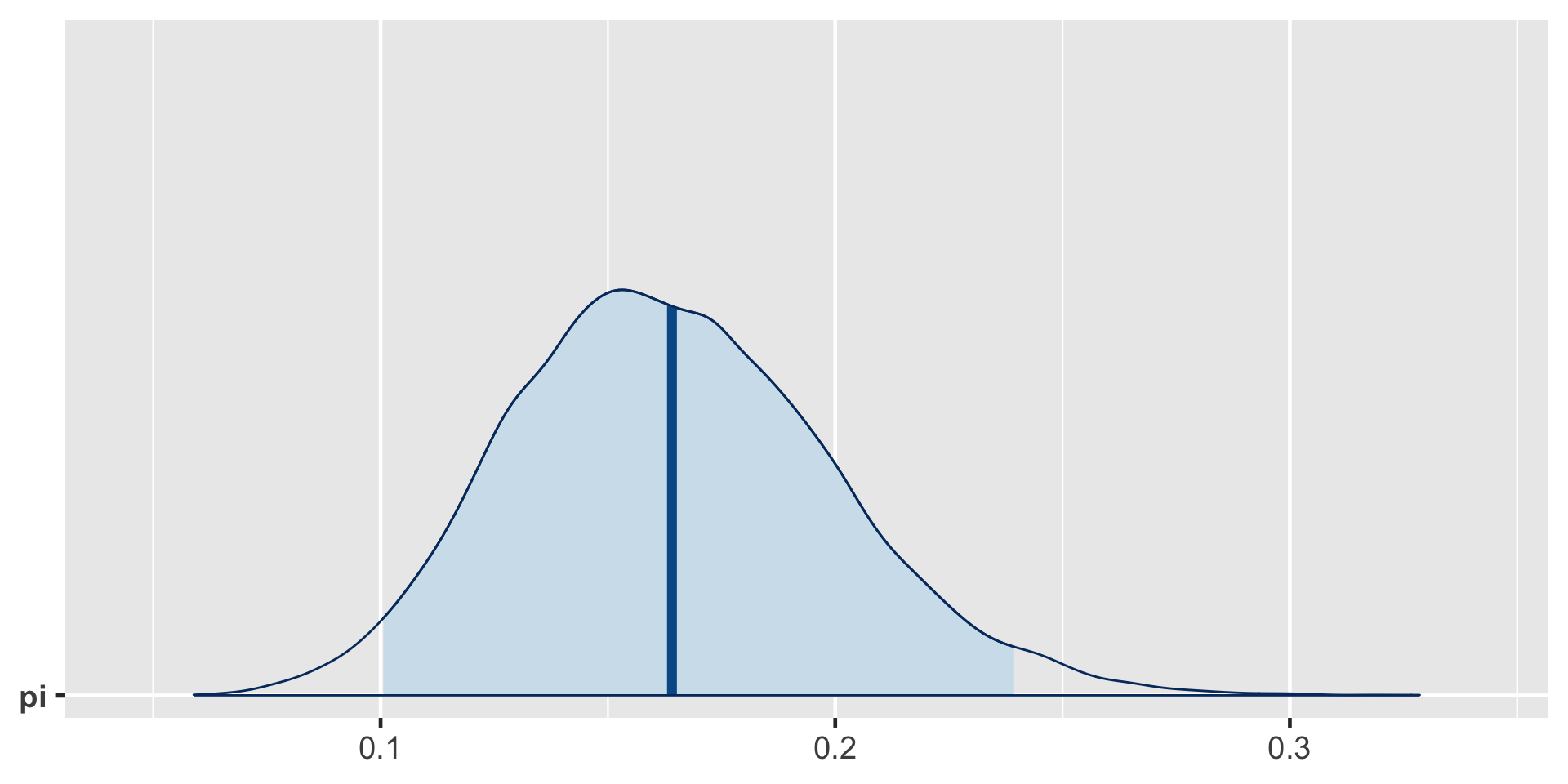
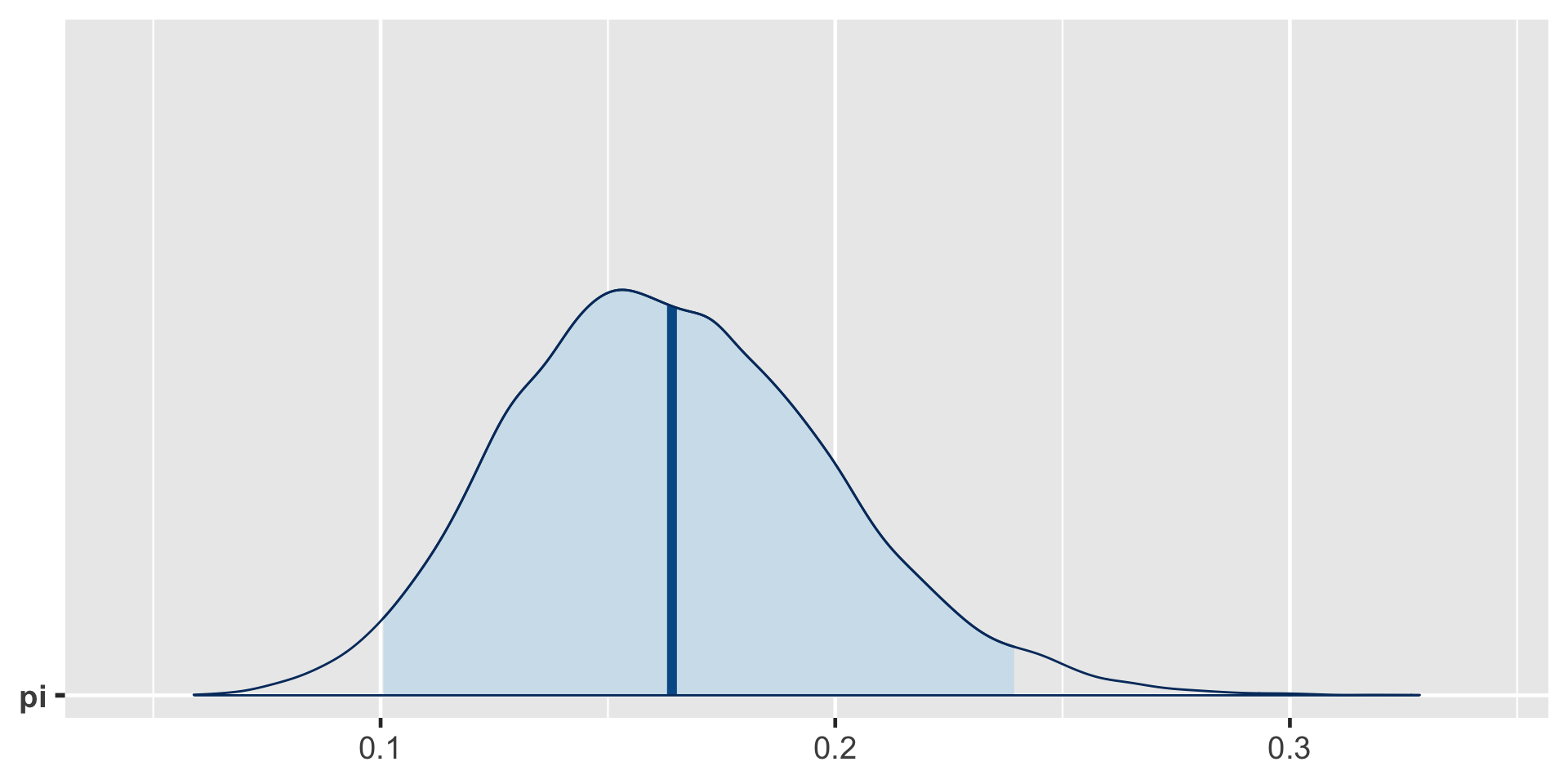
exceeds n percent
FALSE 3079 0.15395
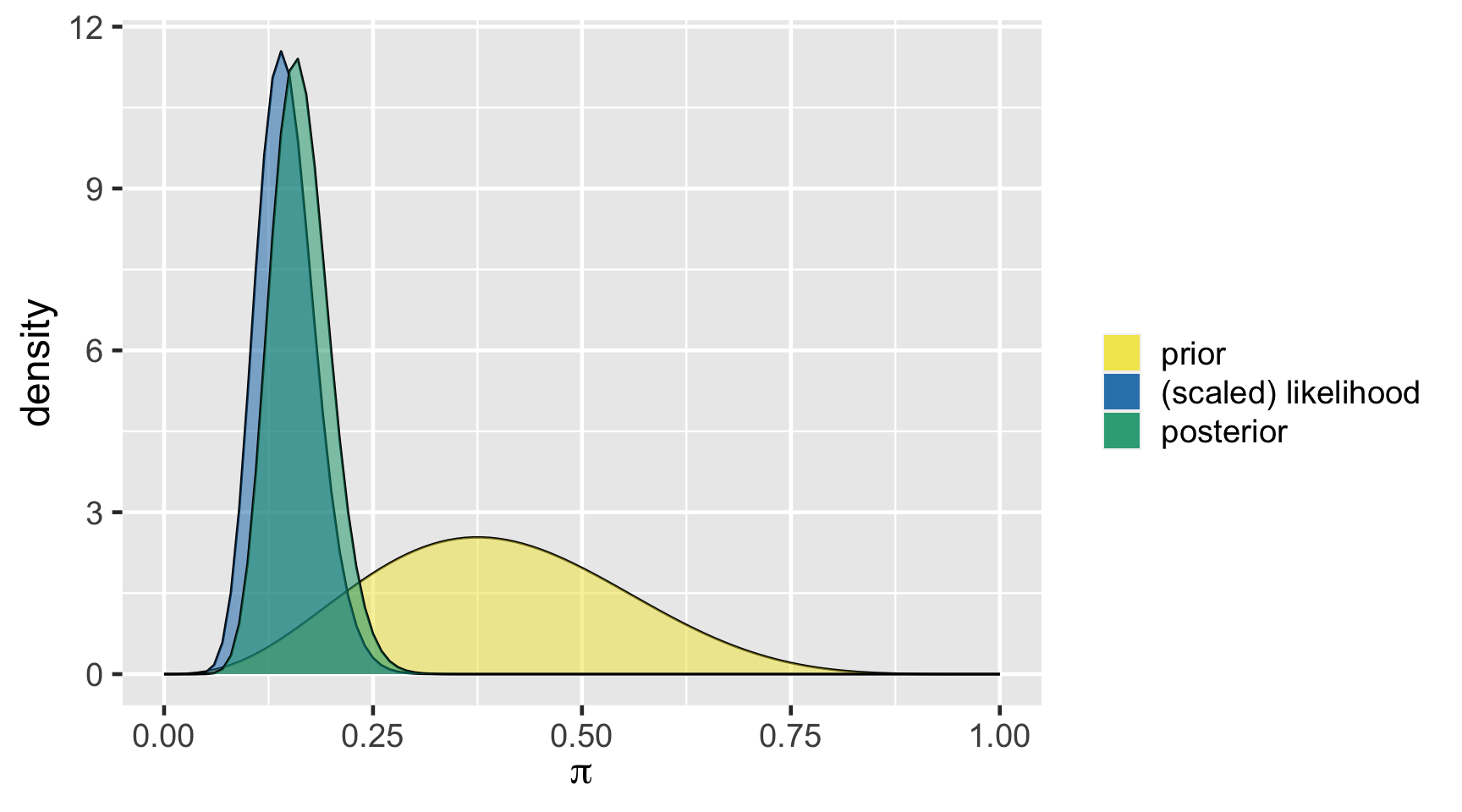
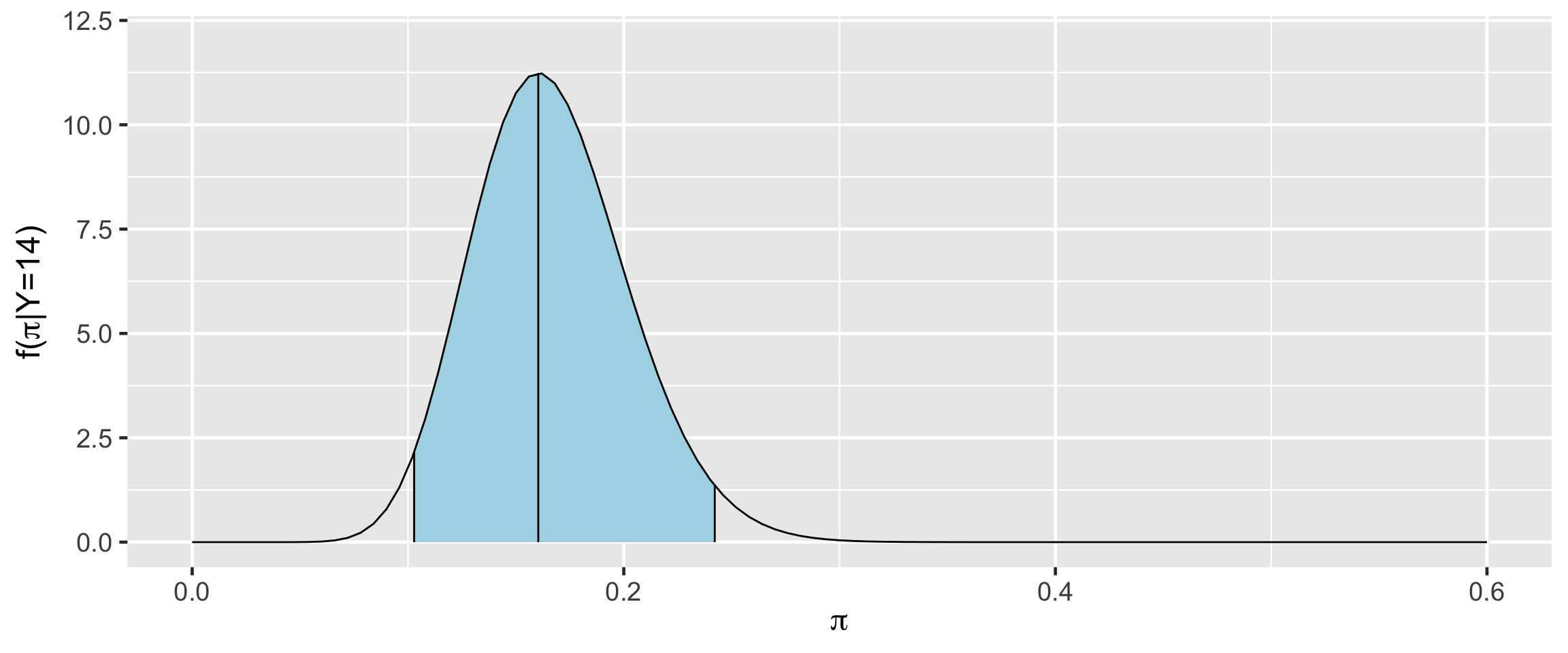
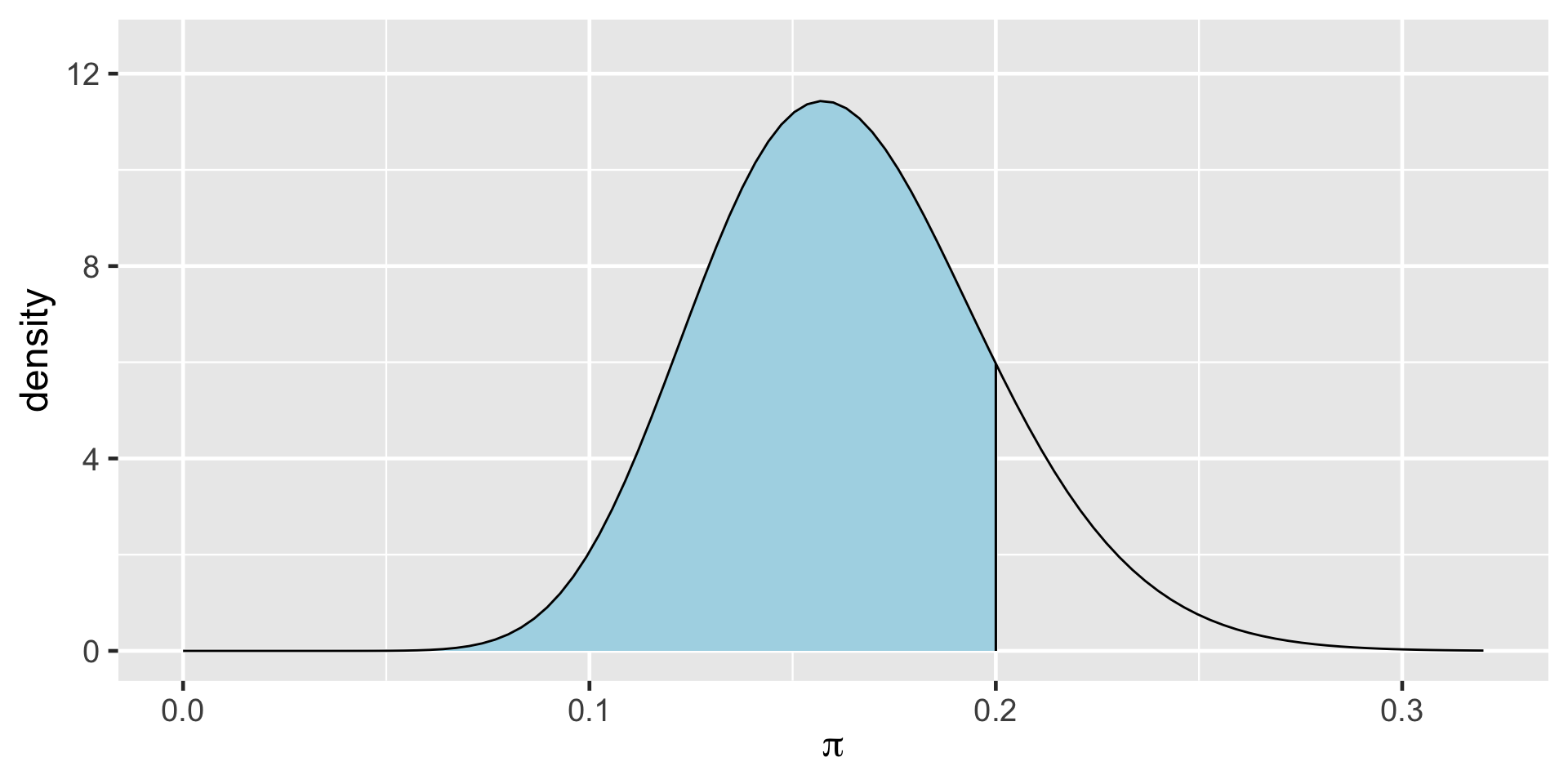
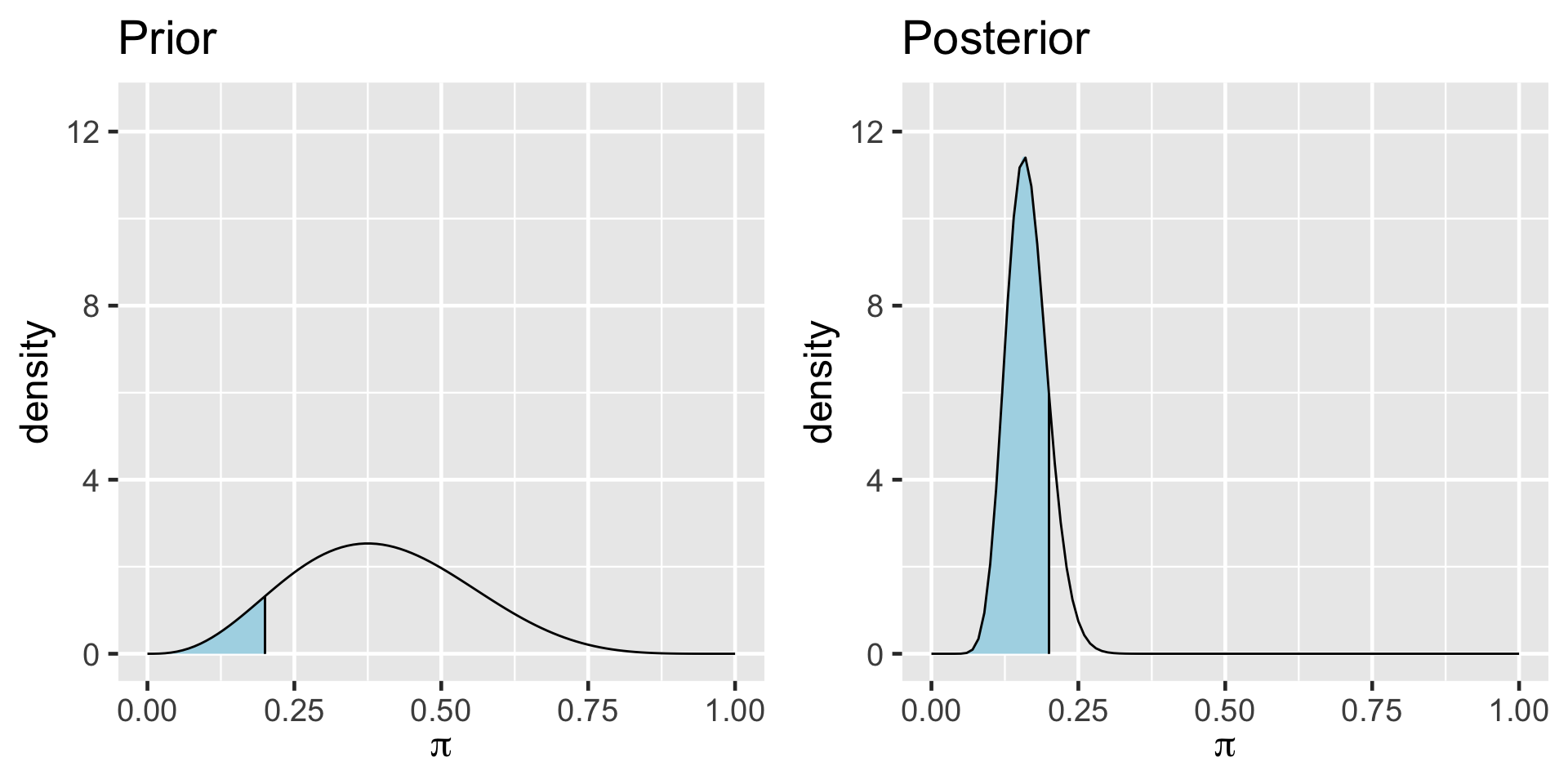
TRUE 16921 0.84605[1] 0.8489856a Bayesian analysis assesses the uncertainty regarding an unknown parameter \(\pi\) in light of observed data \(Y\).
\[P((\pi < 0.20) \; | \; (Y = 14)) = 0.8489856 \;.\]
a frequentist analysis assesses the uncertainty of the observed data \(Y\) in light of assumed values of \(\pi\).
\[P((Y \le 14) | (\pi = 0.20)) = 0.08\]
![]()