library(tidyverse)
MovieRatings <- read.csv("2010_animation_ratings.csv", header = TRUE, sep = ",")
MovieRatings %>%
mutate(Title = as.character(title),
Title = recode(Title,
"Shrek Forever After (a.k.a. Shrek: The Final Chapter) (2010)" = "Shrek Forever",
"How to Train Your Dragon (2010)" = "Dragon",
"Toy Story 3 (2010)" = "Toy Story 3",
"Tangled (2010)" = "Tangled",
"Despicable Me (2010)" = "Despicable Me",
"Legend of the Guardians: The Owls of Ga'Hoole (2010)" = "Guardians",
"Megamind (2010)" = "Megamind",
"Batman: Under the Red Hood (2010)" = "Batman")) ->
MovieRatingsHierarchical Models
Day 5
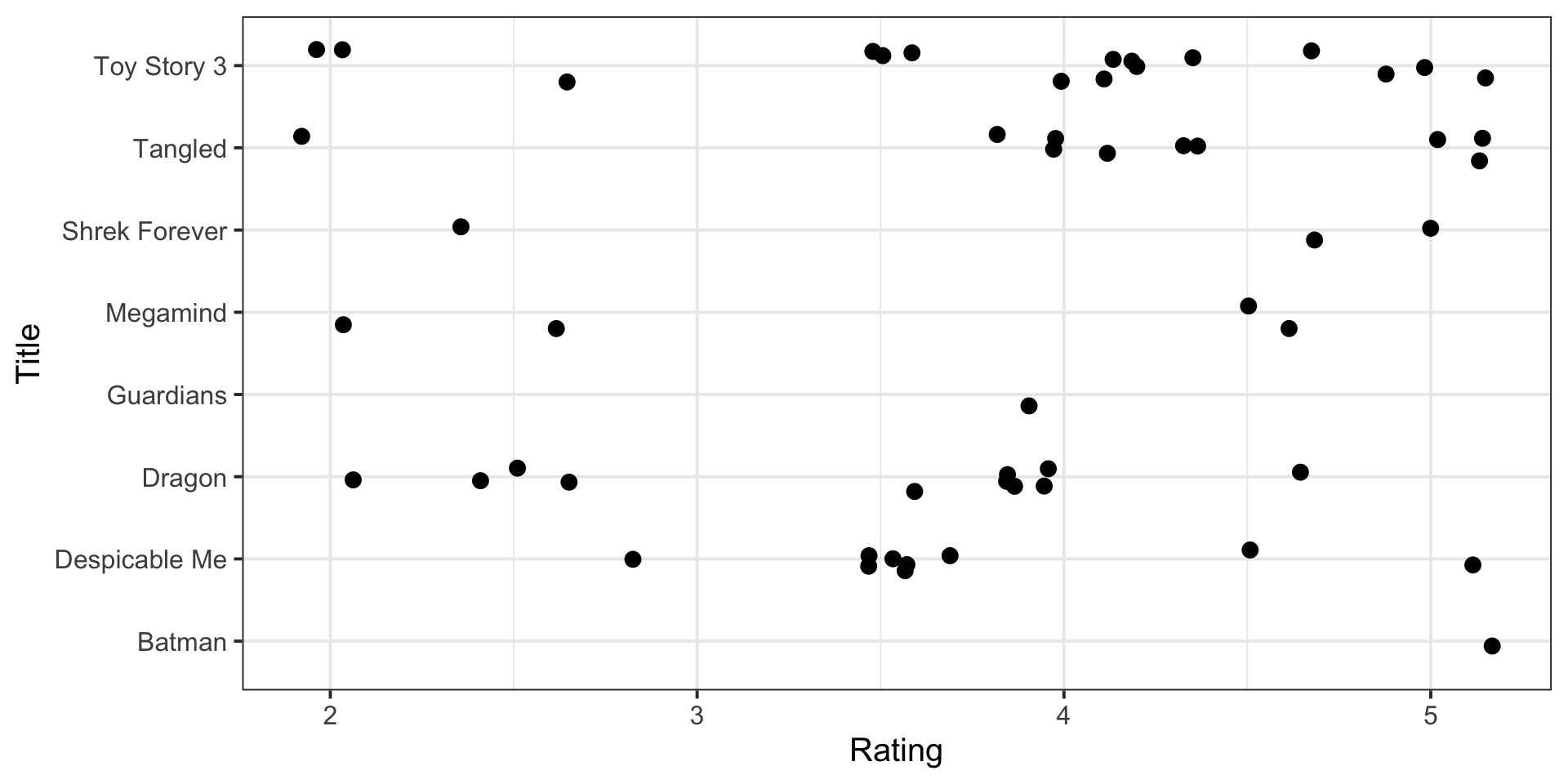
Plot of Ratings by Title
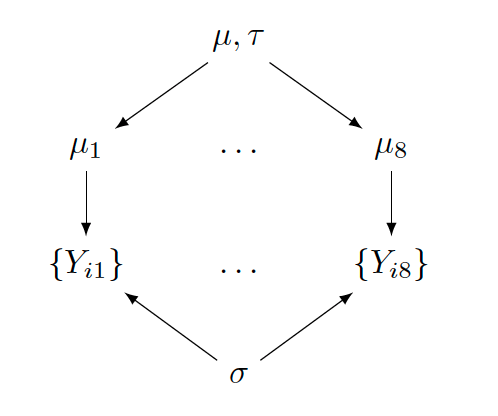
Prior for \(\sigma\) and Graphical Representation
- Weakly informative prior for \(\sigma\): \[\begin{eqnarray} \sigma &\sim& \textrm{Cauchy}(0, 1) \end{eqnarray}\]
Posterior Plots
- Function
mcmc_areas()displays a density estimate of the simulated posterior draws with a specified credible interval
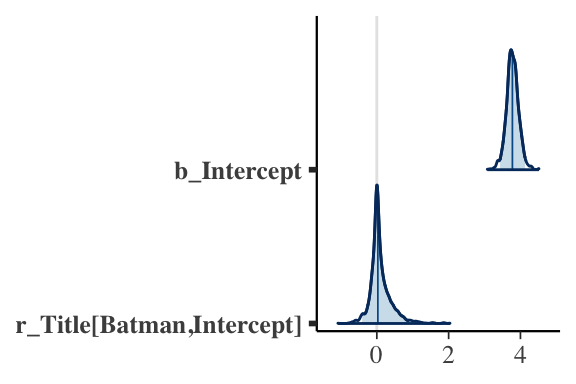
Posterior Plots
library(bayesplot)
mcmc_areas(post_ml,
pars = c("b_Intercept",
"r_Title[Batman,Intercept]",
"r_Title[Despicable.Me,Intercept]",
"r_Title[Dragon,Intercept]",
"r_Title[Guardians,Intercept]",
"r_Title[Megamind,Intercept]",
"r_Title[Shrek.Forever,Intercept]",
"r_Title[Tangled,Intercept]",
"r_Title[Toy.Story.3,Intercept]"),
prob = 0.95)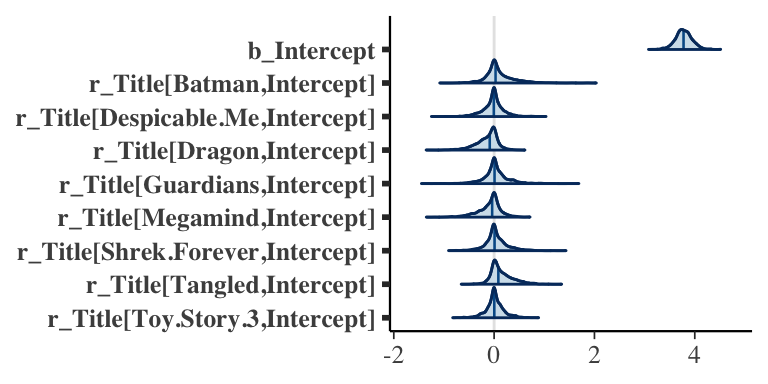
Posterior Plots
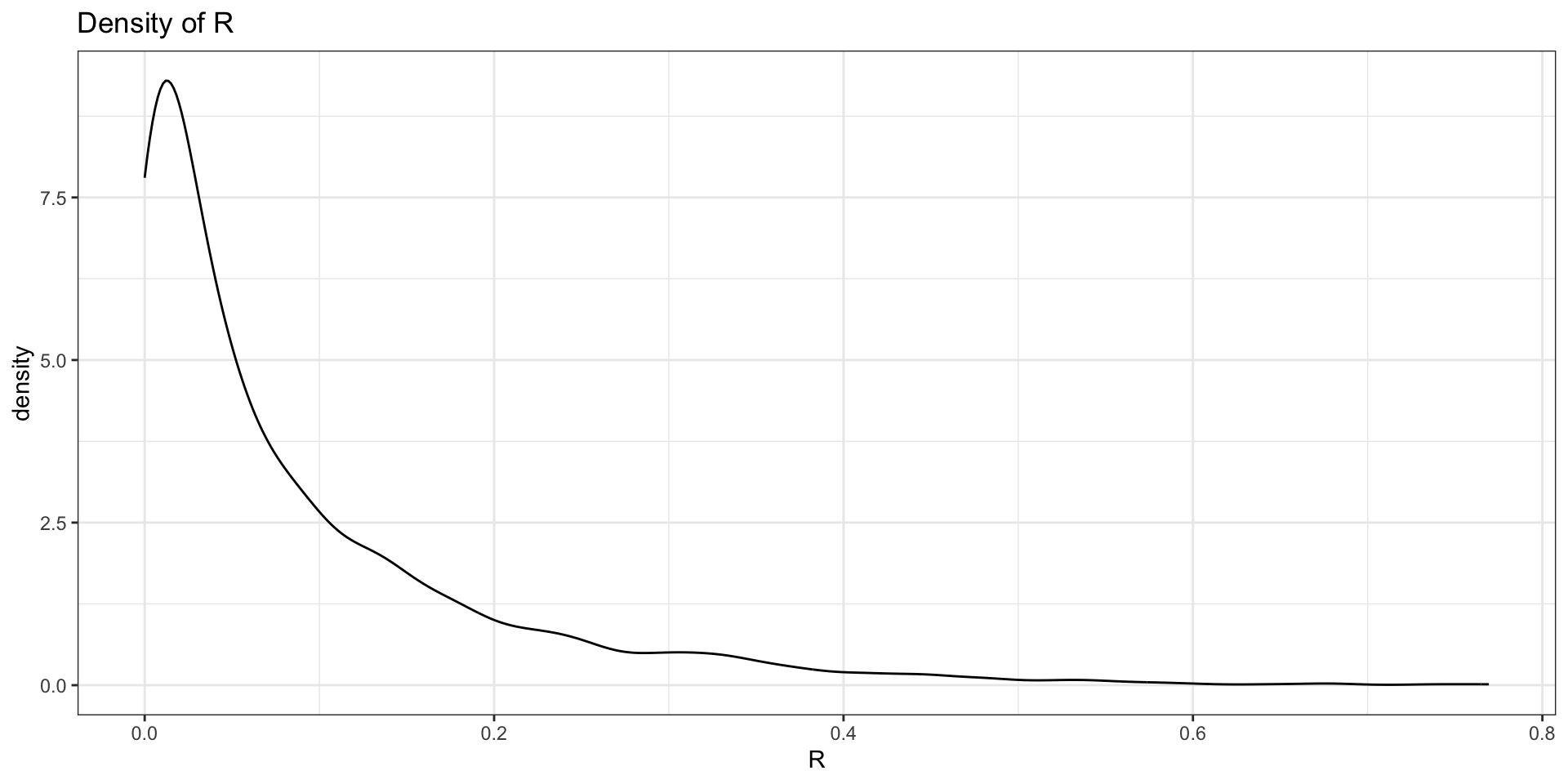
- Between-group variability \(\tau\) vs within-group variability \(\sigma\)
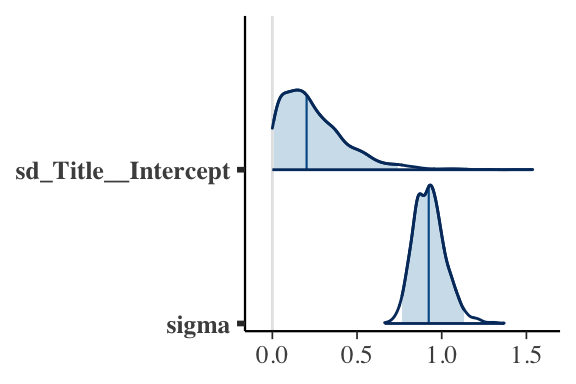
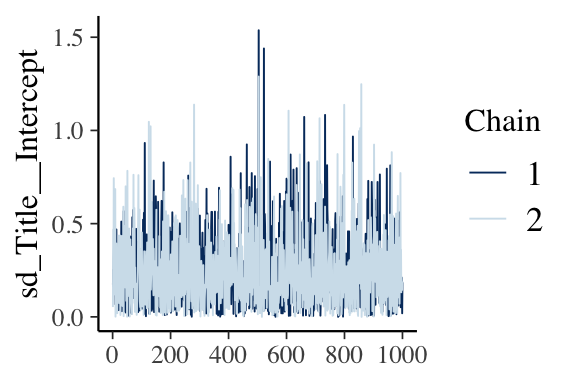
MCMC Diagnostics: Traceplot
- Function
mcmc_trace()displays a traceplot of the simulated posterior draws for each chain
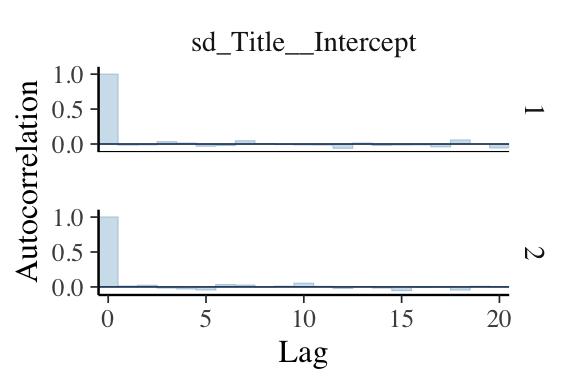
MCMC Diagnostics: Autocorrelation Plot
- Function
mcmc_acf()displays an autocorrelation plot of the simulated posterior draws
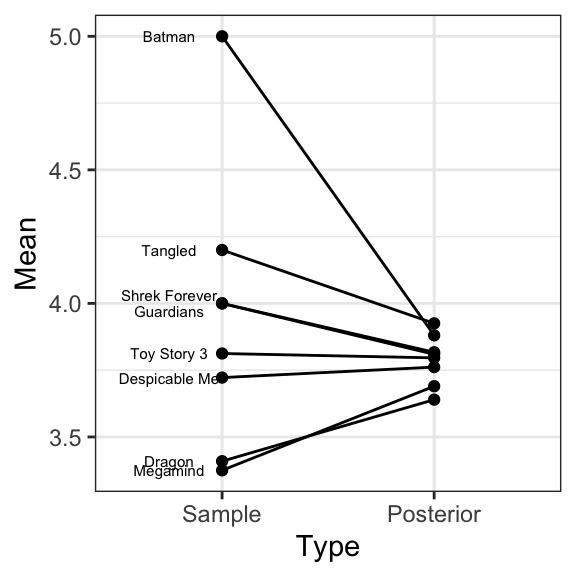
Shrinkage/Pooling Effects
Sources of Variability: Results
![]()