Scientists in the US National Toxicology Program routinely evaluate existing and new chemicals for potential human toxicity. These evaluations involve a variety of test paradigms, ranging from high-throughput in vitro tests to animal bioassays. A study of benzophenone, which has many uses ranging from producing “sweet-woody-geranium-like notes” in perfume to preventing UV damage to other chemicals, involved 150 female rats exposed to various doses of benzophenone and 50 unexposed (control) rats. The outcome of interest to us is a particular tumor, histiocytic sarcoma.
A typical analysis of these data might be use of Fisher’s exact test to evaluate whether there is an association between benzophenone exposure and tumor development. We use this test to evaluate the hypothesis.
Fisher's Exact Test for Count Data
data: tumordat
p-value = 0.5746
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.000000 7.302064
sample estimates:
odds ratio
0
Here we see a large p-value, indicating that assuming there is no difference in tumor rates between the groups, our data, or data that are more extreme, are not unlikely.
Unusual Results
Scientists in the National Toxicology Program saw the results quite differently. Histiocytic sarcomas are exceedingly rare. One researcher pointed out that across 6 prior studies involving 460 female rats, no animals in the control groups ever developed this type of tumor.
Incorporating Historical Data
Bayesian methods give us a great mechanism for incorporating historical data into an analysis!
Recall the beta-binomial model: let \(\pi \sim \text{Beta}(\alpha, \beta)\) and \(Y|n \sim \text{Bin}(n,\pi)\). Then \(\pi|y \sim \text{Beta}(\alpha +y, \beta+n-y)\), and \(\alpha\) and \(\beta\) can be interpreted as the prior number of successes (here, tumors) and failures, respectively.
We can think of a beta-binomial model for each group, the control group and the benzophenone group.
Note: if you’ve done a lot of modeling, you might think first of a logistic regression model – a good choice here, but we haven’t yet discussed regression modeling, so we’ll stick with analyzing each group using a beta-binomial model.
Benzophenone Group
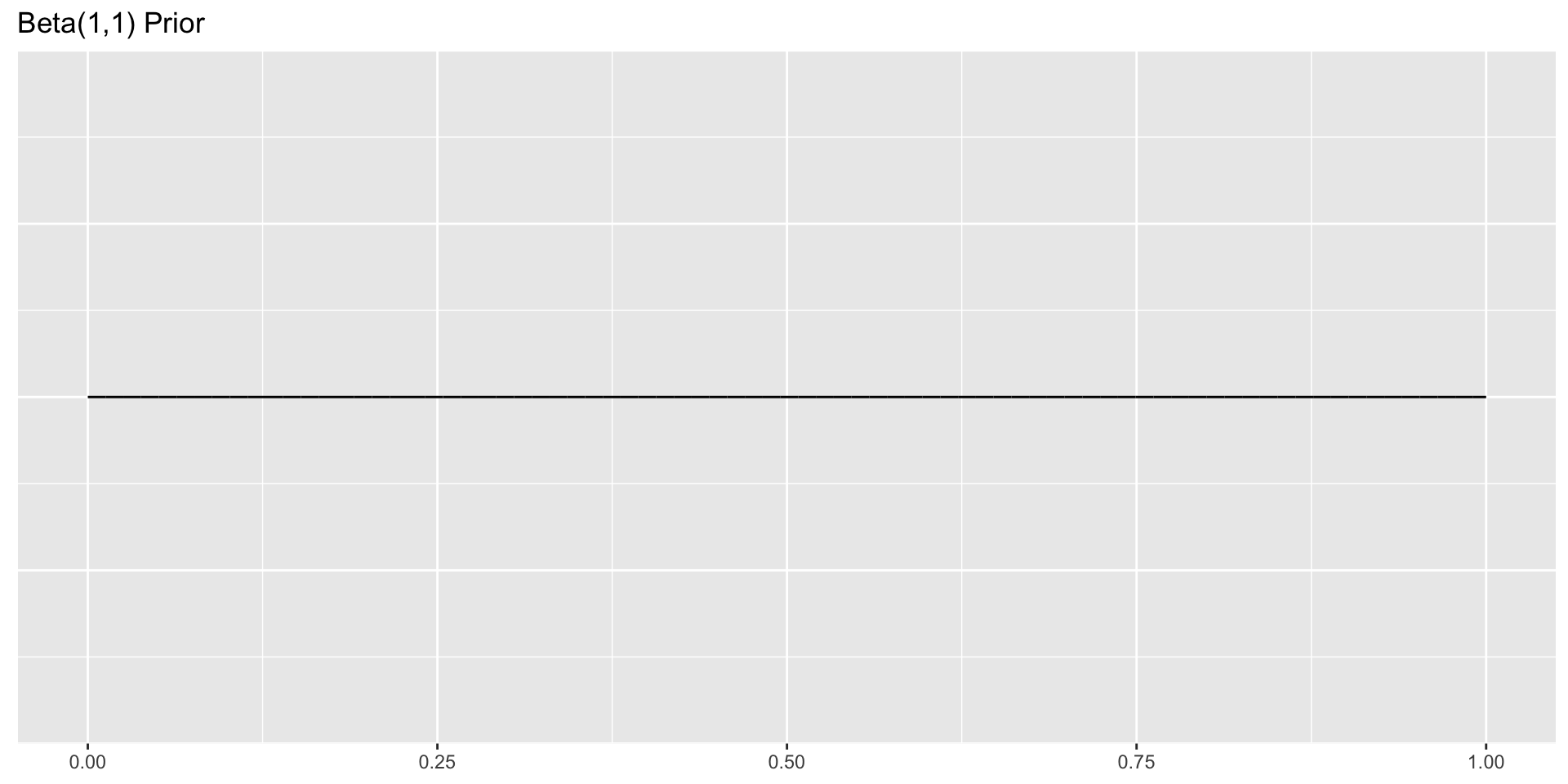
Given that we don’t know much about this chemical, we may want to specify a uniform prior, such as a Beta(1,1).
Control Group
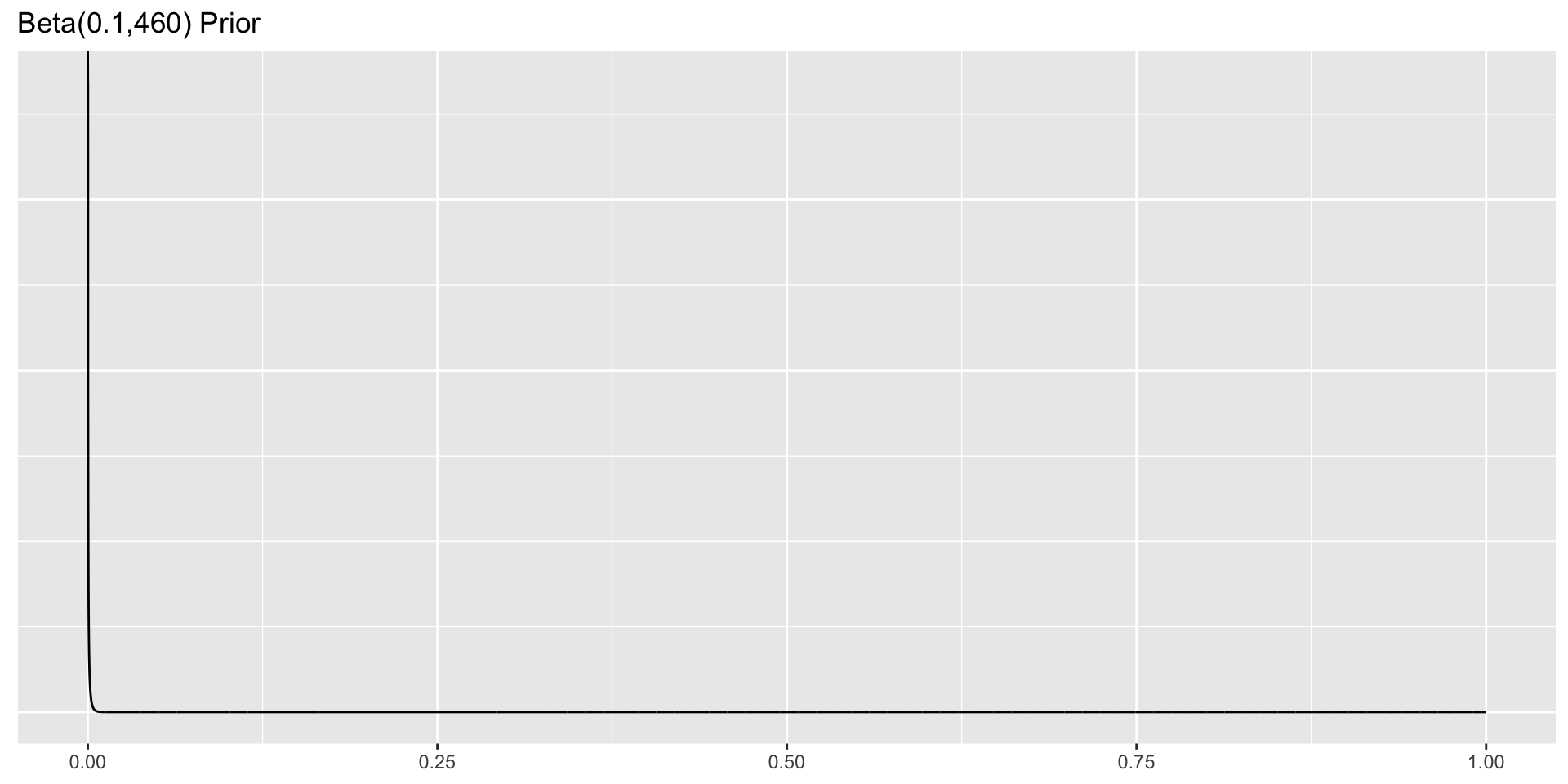
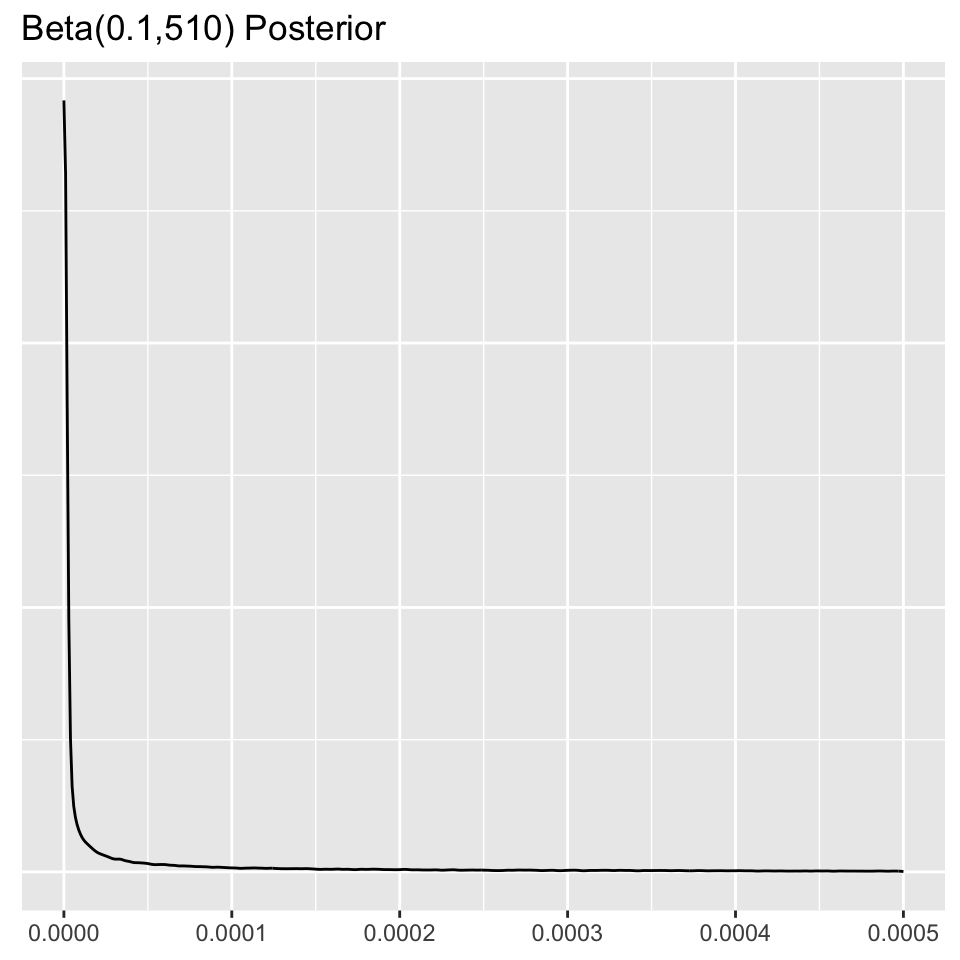
We have historical data from prior studies that indicates that of 460 female rats on control, 0 have developed tumors. Because the parameters of the beta distribution must be positive, we can specify a Beta(0.1,460) prior in this group, plotted below.
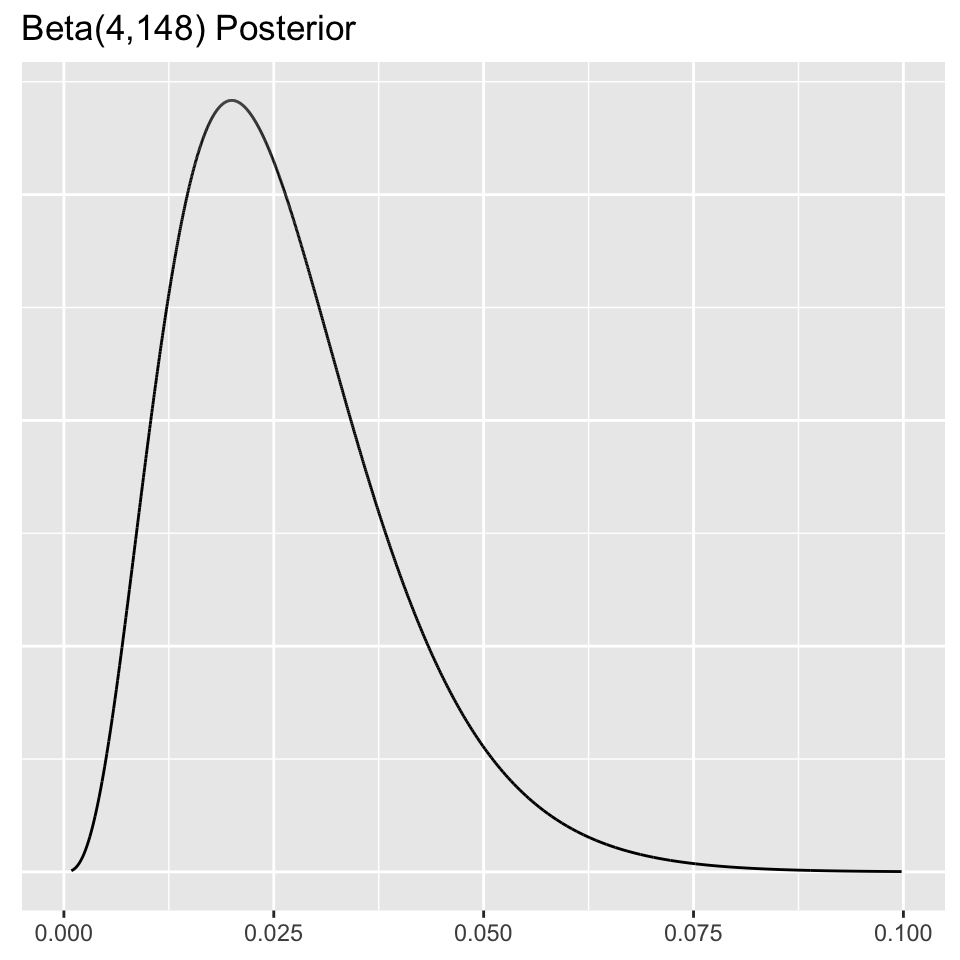
Beta(1,1) prior with 3 successes and 147 failures yields a Beta(1+3,1+147)=Beta(4,148) posterior, and the posterior mean estimate of the probability of a tumor in this group is \(\frac{4}{148+4}=\frac{4}{152}=0.026\).
Beta(0.1,460) prior with 0 successes and 50 failures yields a Beta(0.1+0,460+50)=Beta(0.1,510) posterior, and the posterior mean estimate of the probability of a tumor in this group is \(\frac{0.1}{510.1}=0.0002\).
Simulation-Based Inference
We can evaluate the hypothesis that the posterior mean tumor rate in the benzophenone group is greater than that in the control group by simulating values of the proportions from the respective beta posteriors and counting how many times we see a greater tumor proportion parameter value in the benzophenone group than among controls.
Take 5 minutes to consider an example involving Bayesian inference that you might use in one of your courses (tomorrow we will design a posterior analysis activity, so you might think about examples that work well for that goal)
Split into (new!) groups of 3-4 and share your ideas