[1] 2.594241e-146Inference: frequentist vs. Bayesian
Day 5
The \(H_0\) Sampling Distribution
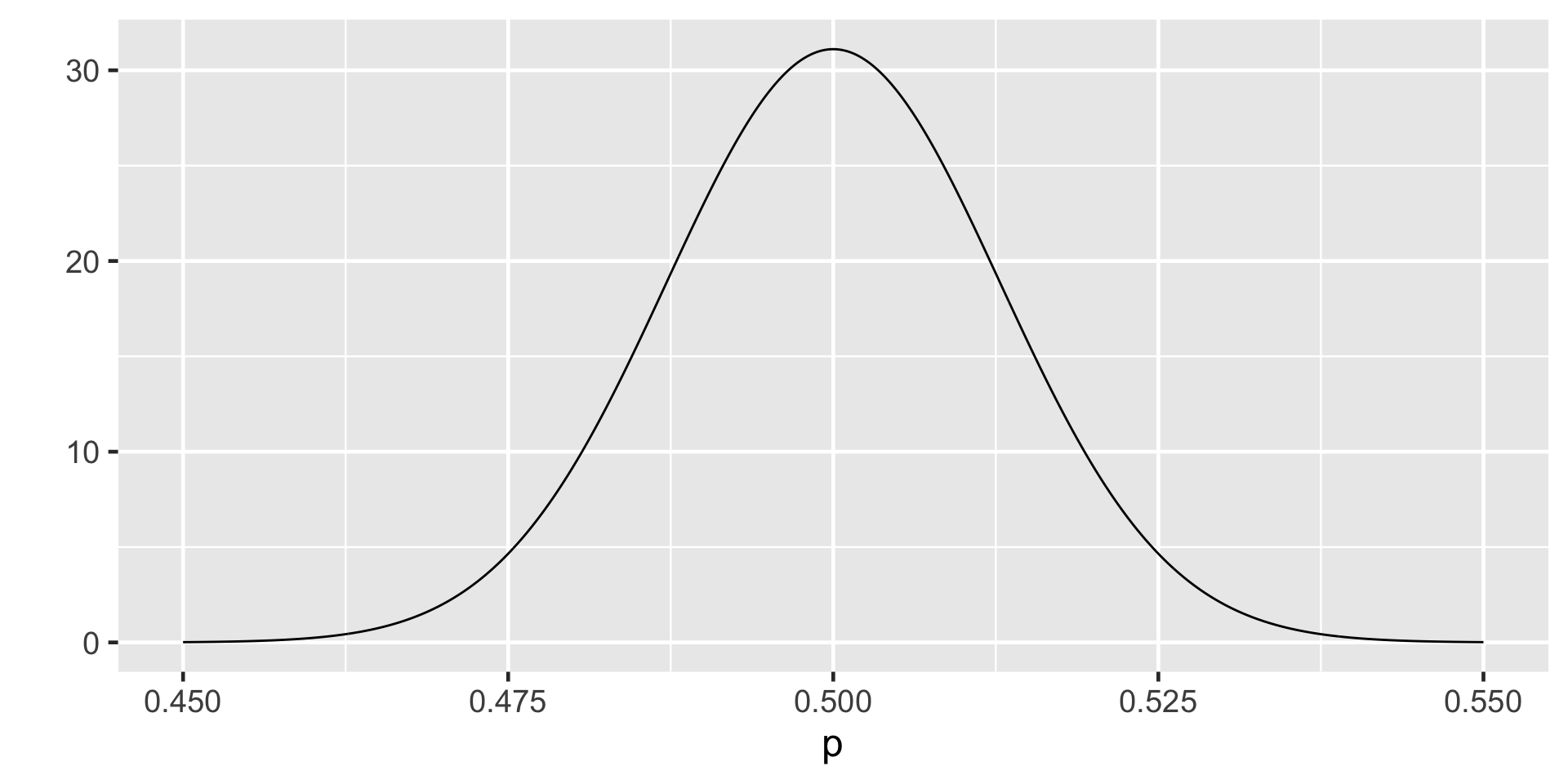
Sampling Distribution
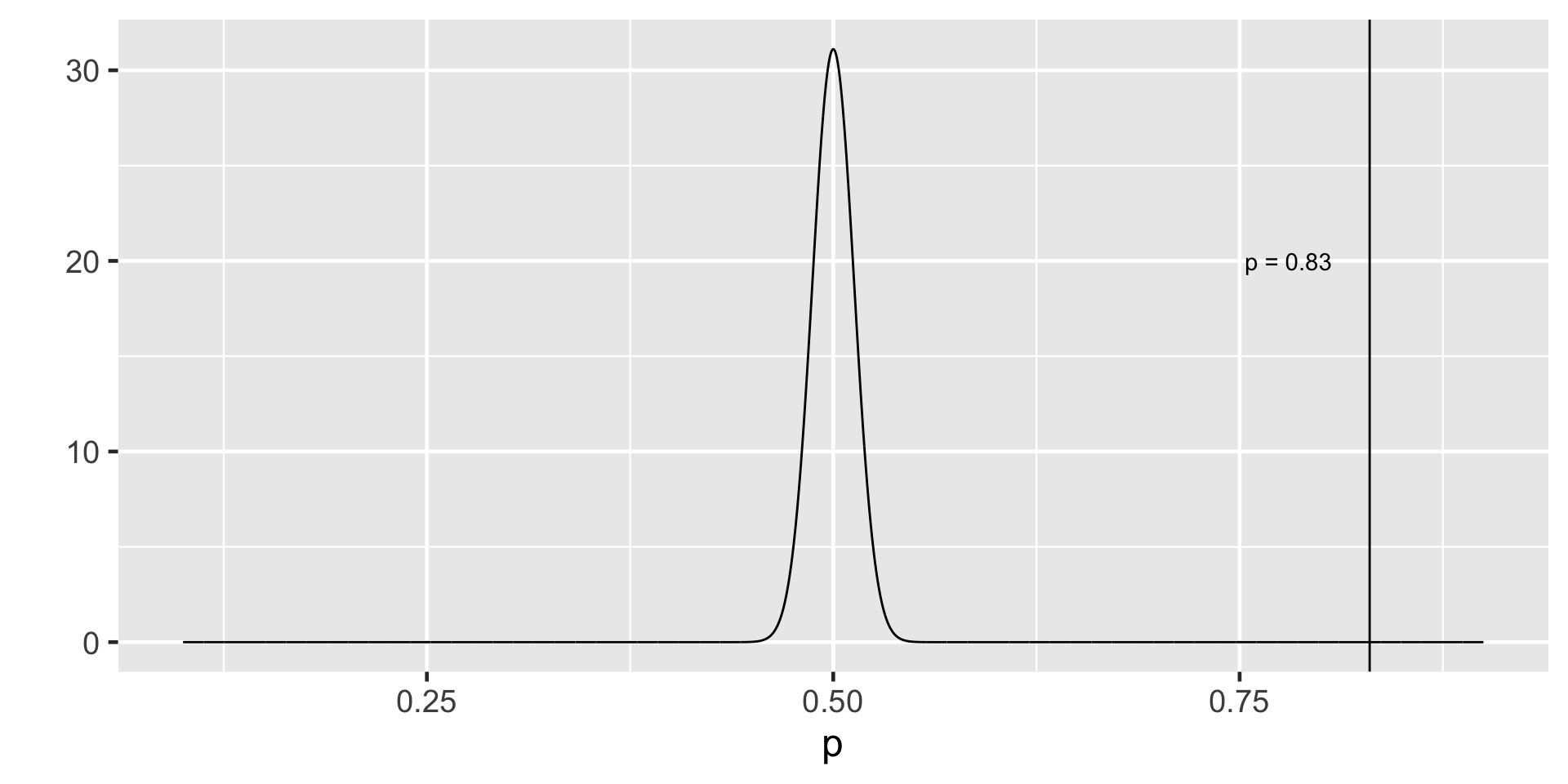
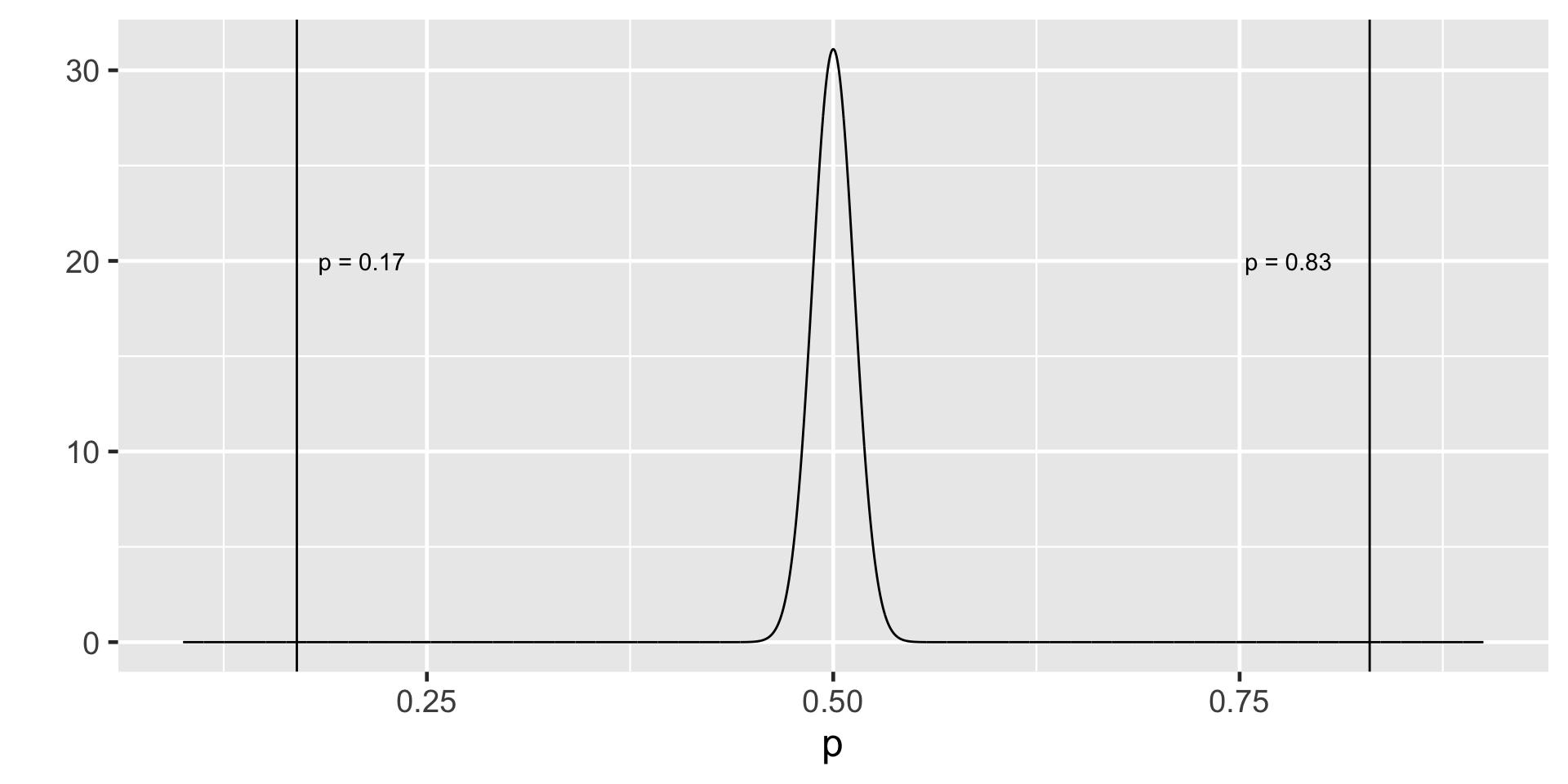
Remembering CLT
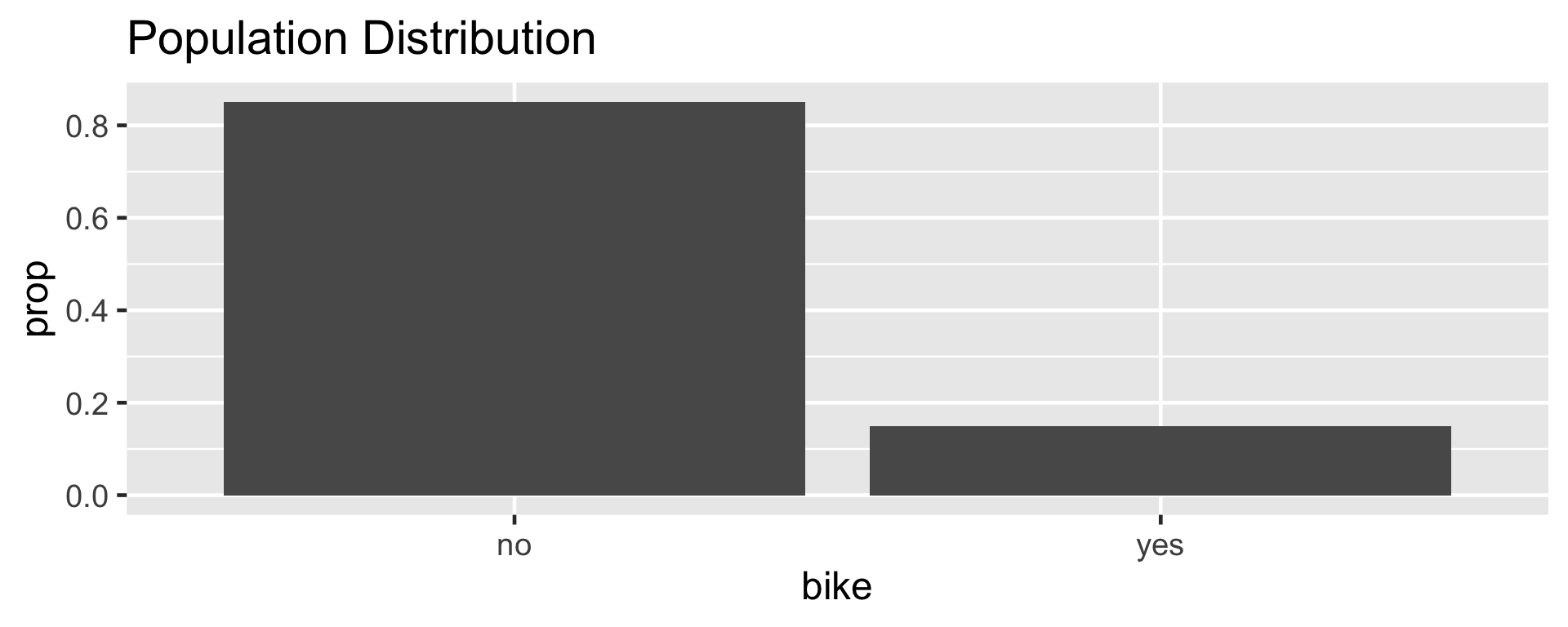
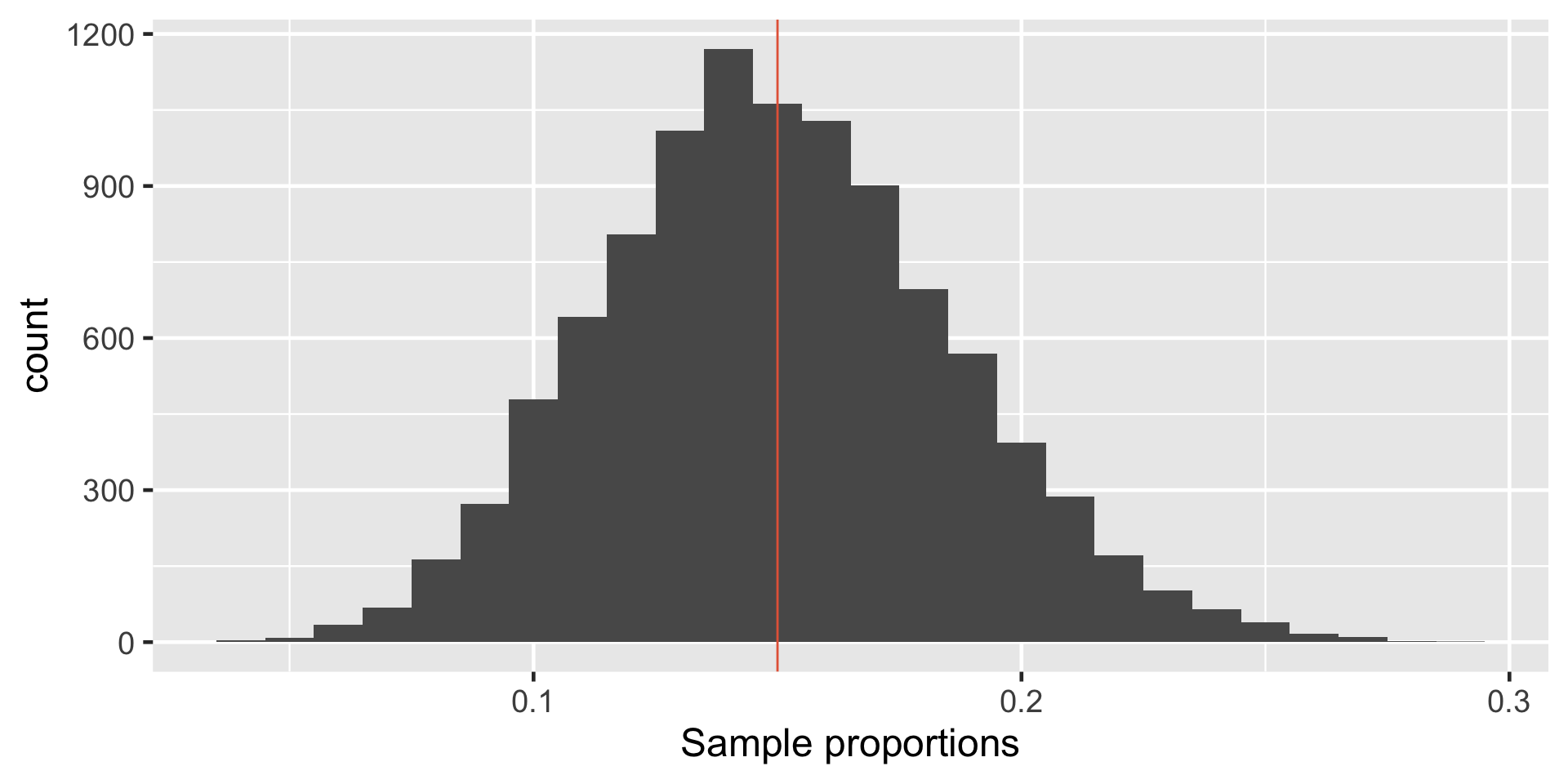
Let \(\pi\) represent the proportion of bike owners on campus then \(\pi =\) 0.15.
Getting to sampling distribution of single proportion
\(p_1\) - Proportion of first sample (n = 100)
[1] 0.17\(p_2\) -Proportion of second sample (n = 100)
[1] 0.12\(p_3\) -Proportion of third sample (n = 100)
[1] 0.14Sampling Distribution of Single Proportion
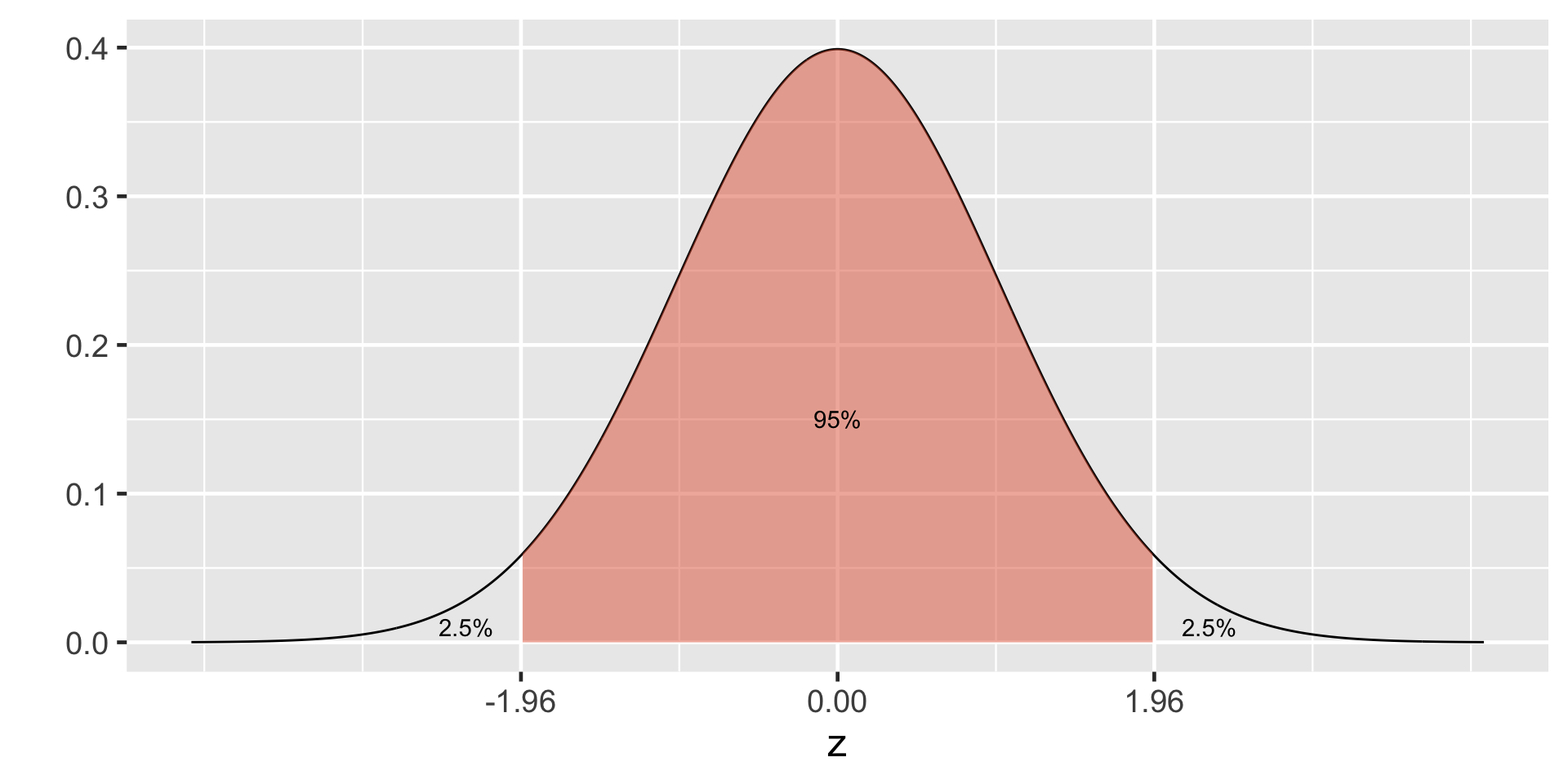
95% of the data falls within 1.96 standard deviations in the normal distribution.
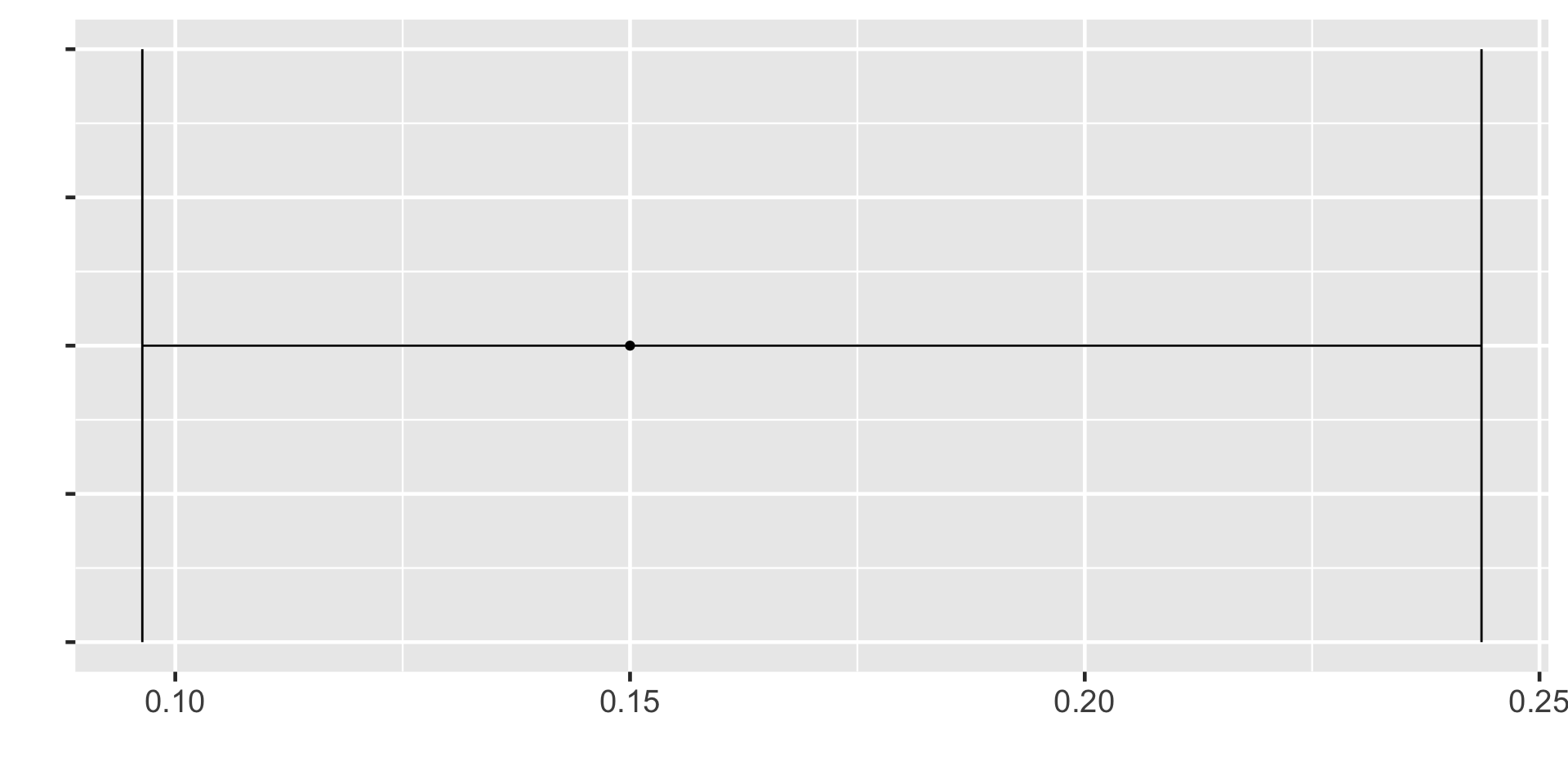
95% CI for the first sample
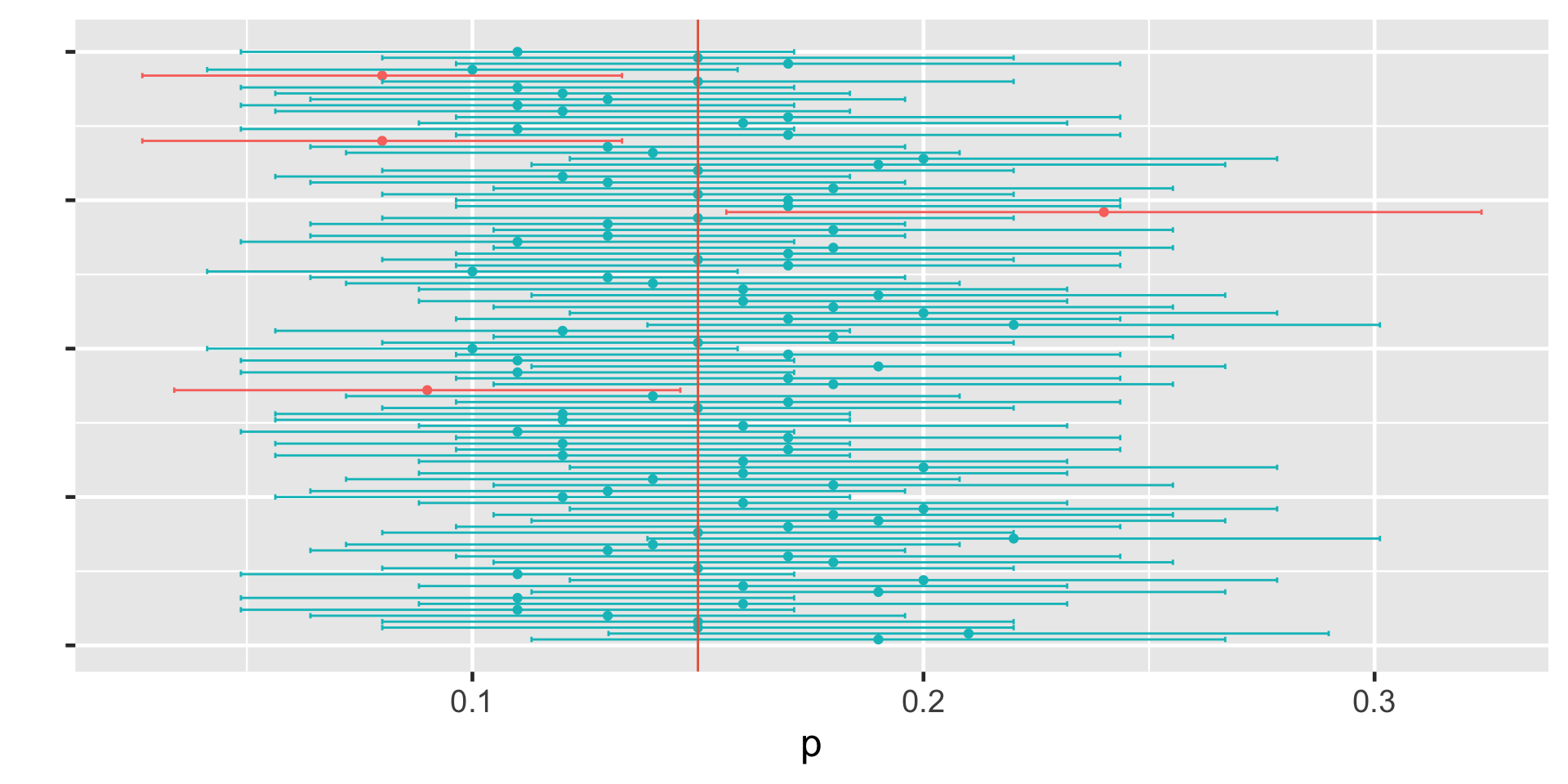
95%CI = (0.09637597, 0.243624)
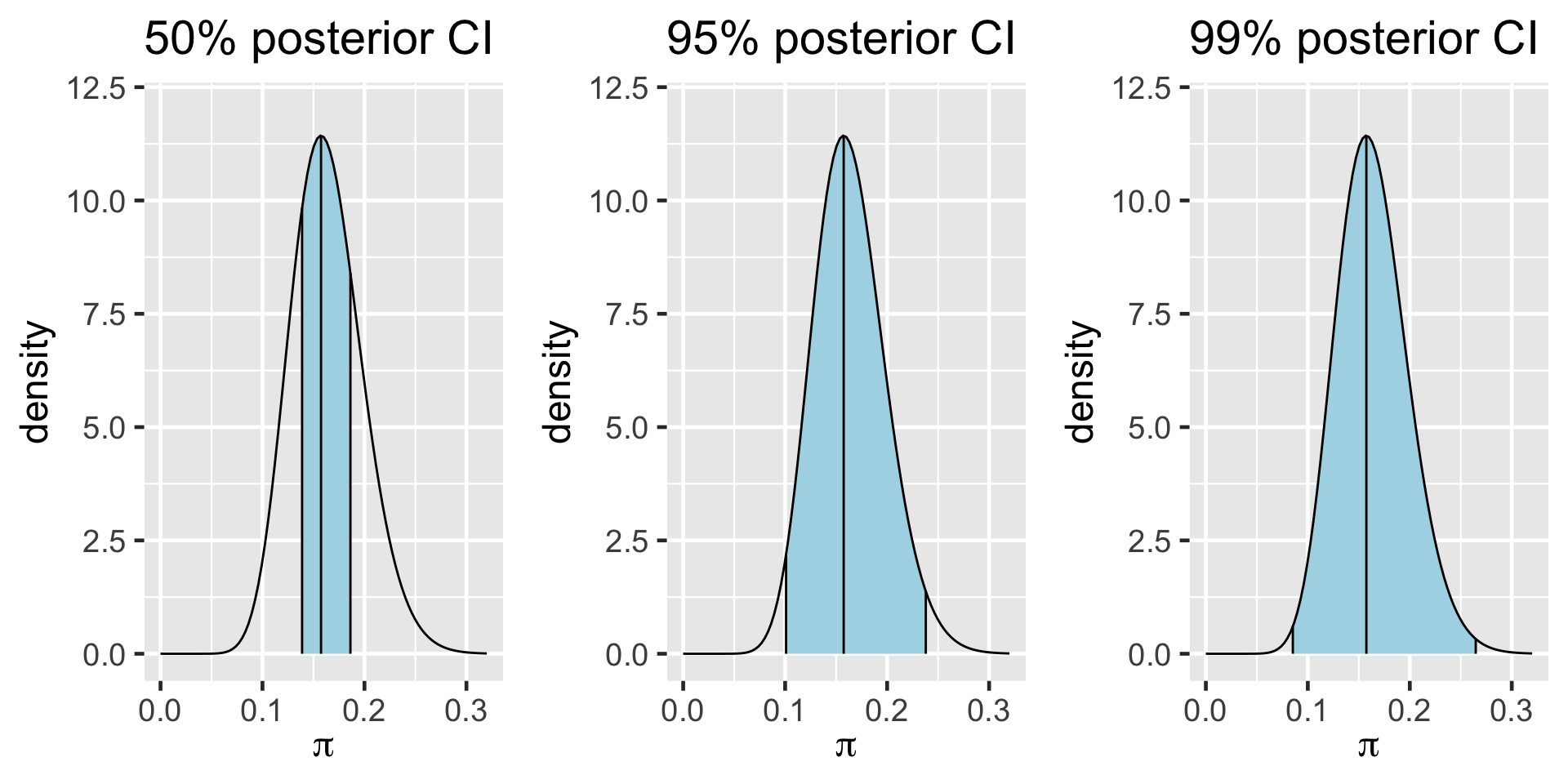
Understanding Confidence Intervals
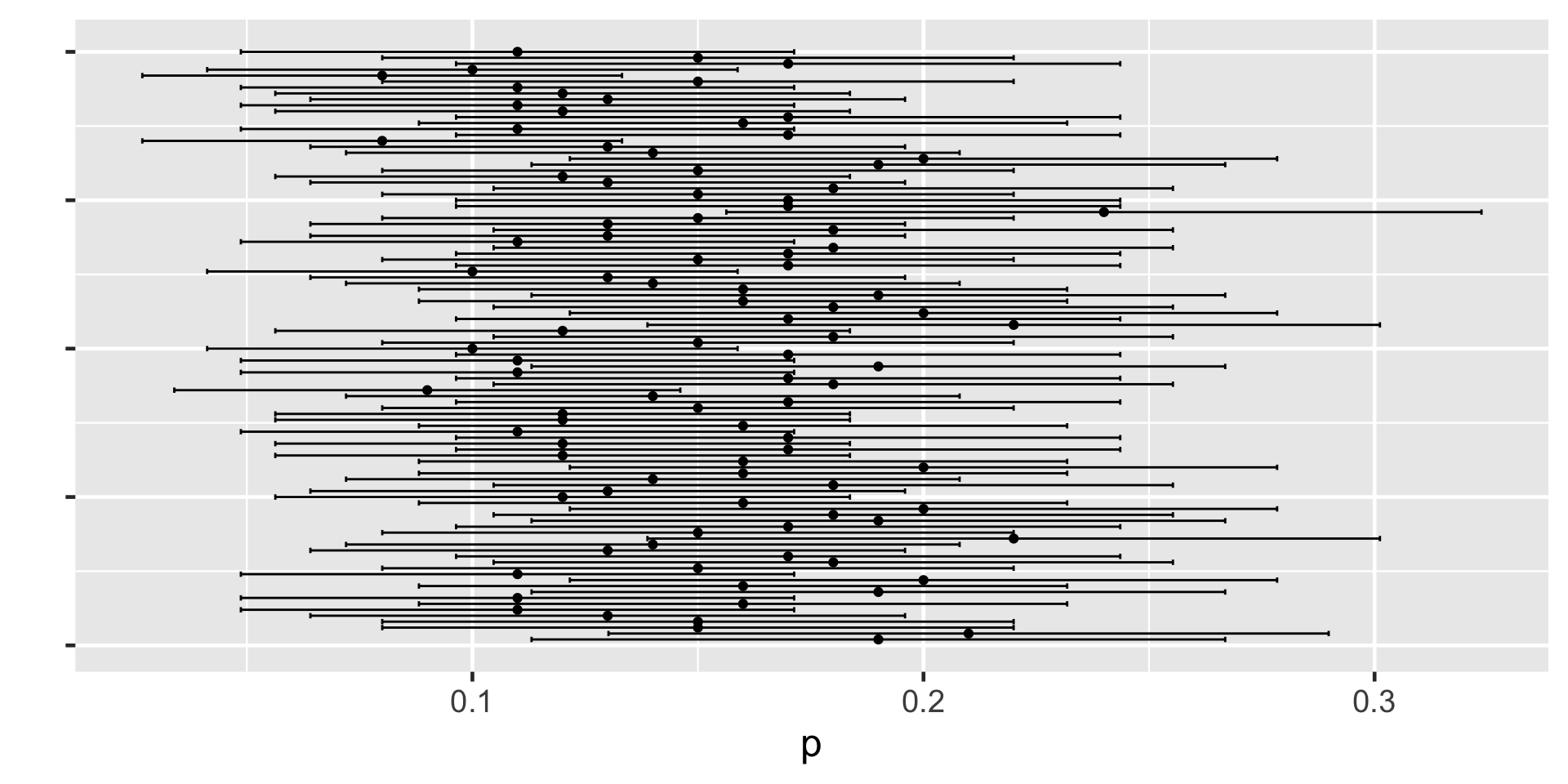
Understanding Confidence Intervals
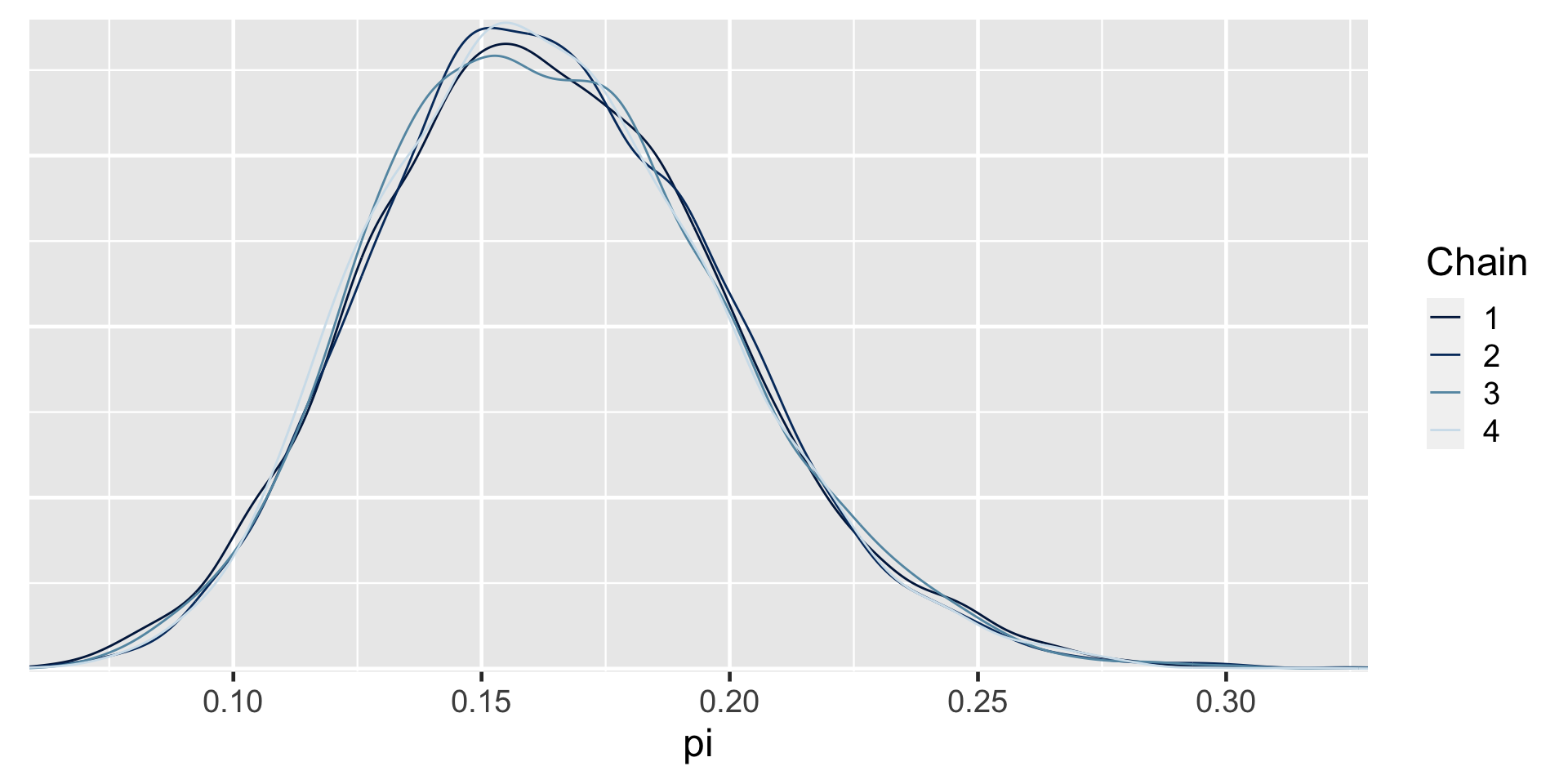
library(rstan)
# STEP 1: DEFINE the model
art_model <- "
data {
int<lower=0, upper=100> Y;
}
parameters {
real<lower=0, upper=1> pi;
}
model {
Y ~ binomial(100, pi);
pi ~ beta(4, 6);
}
"
# STEP 2: SIMULATE the posterior
art_sim <- stan(model_code = art_model, data = list(Y = 14),
chains = 4, iter = 5000*2, seed = 84735,
refresh = FALSE)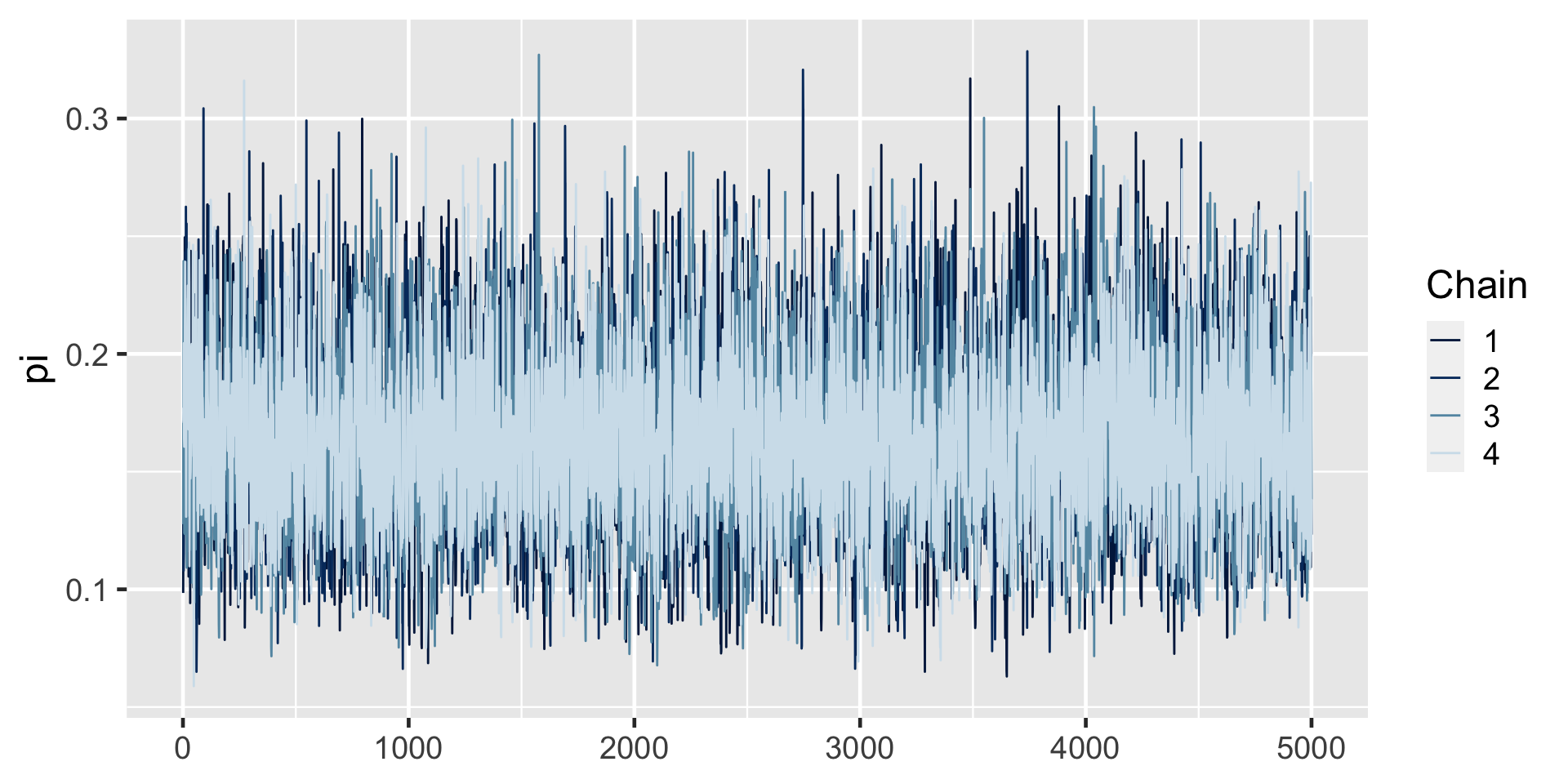
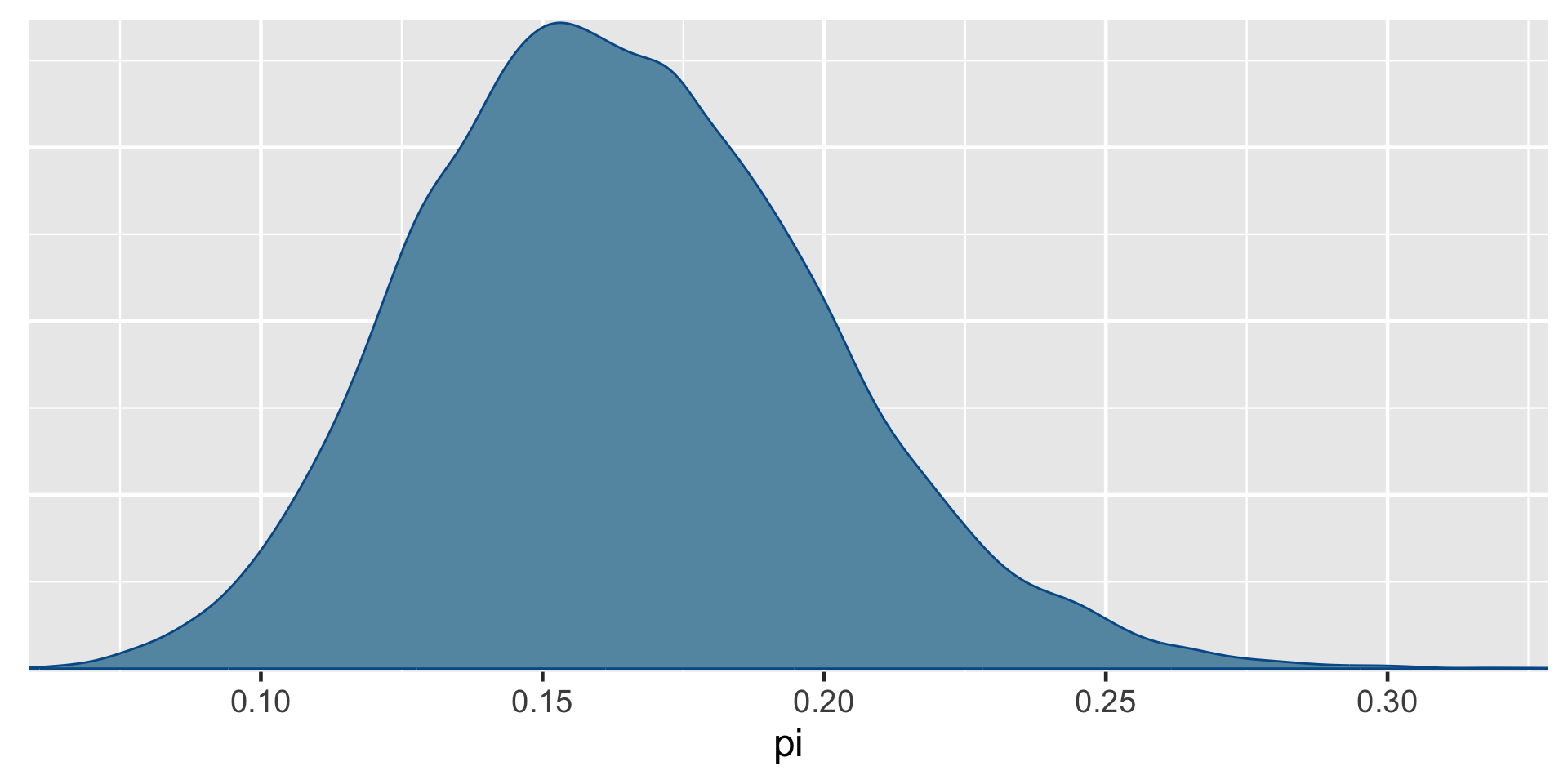
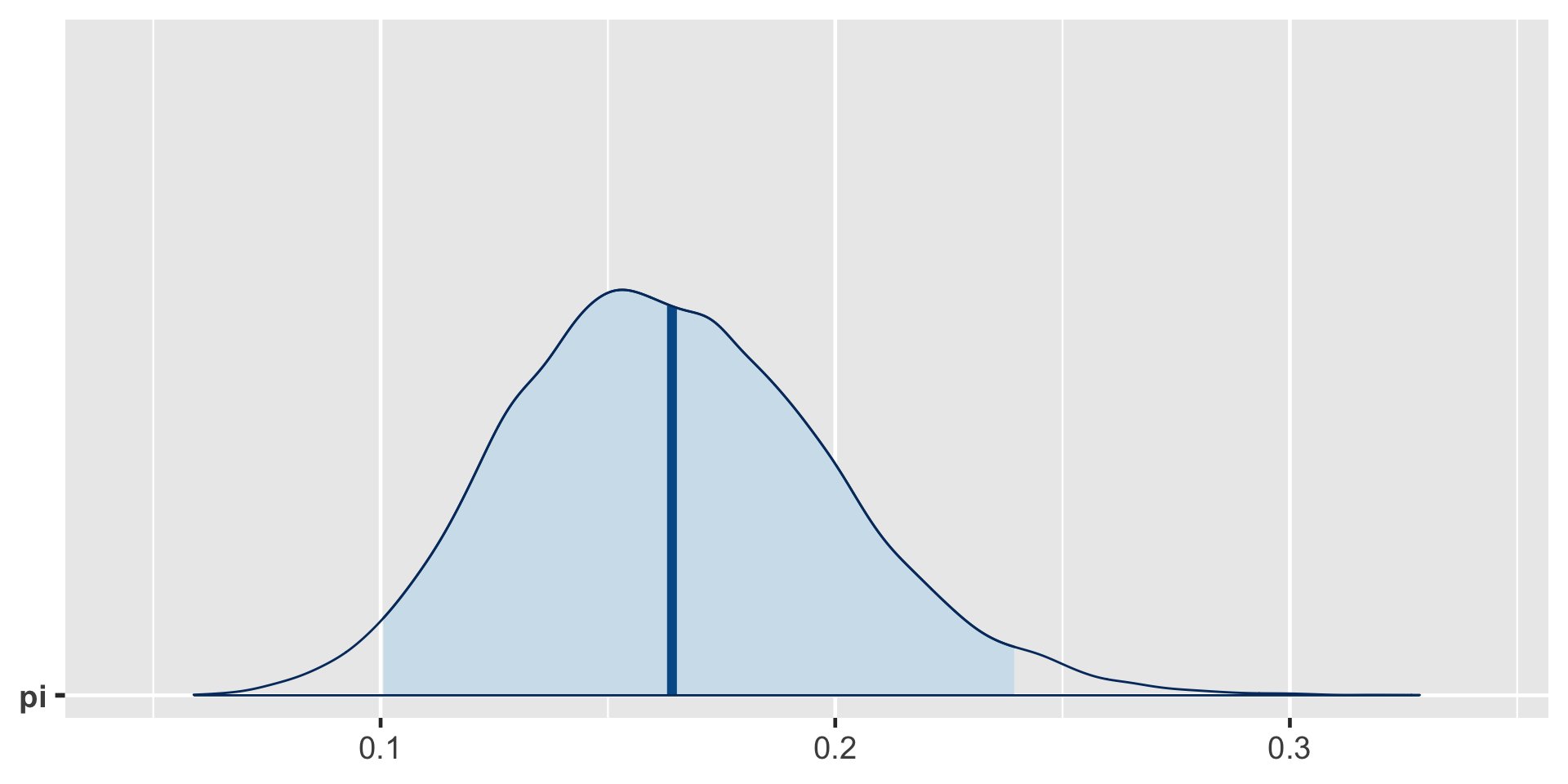
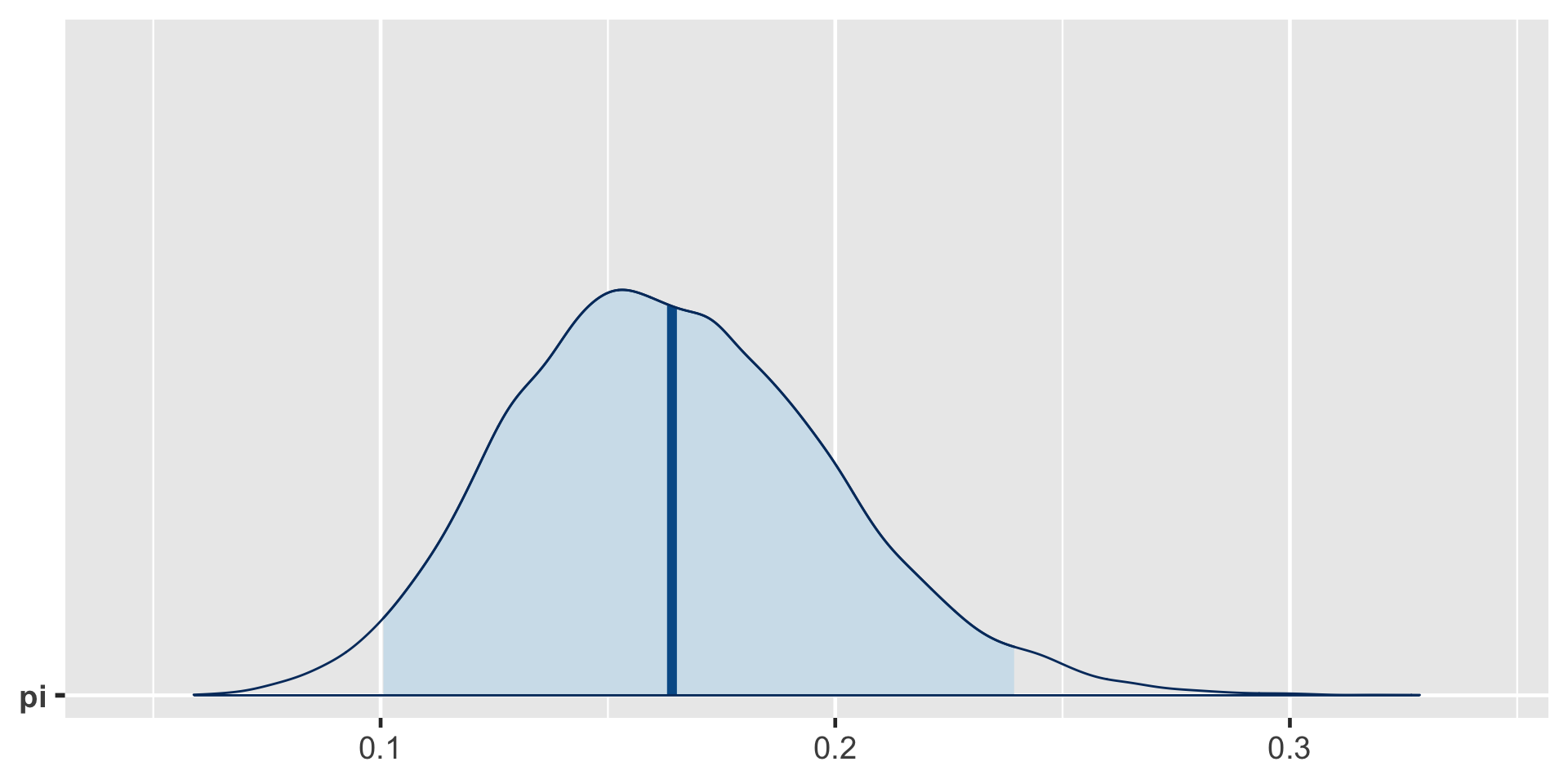
exceeds n percent
FALSE 3079 0.15395
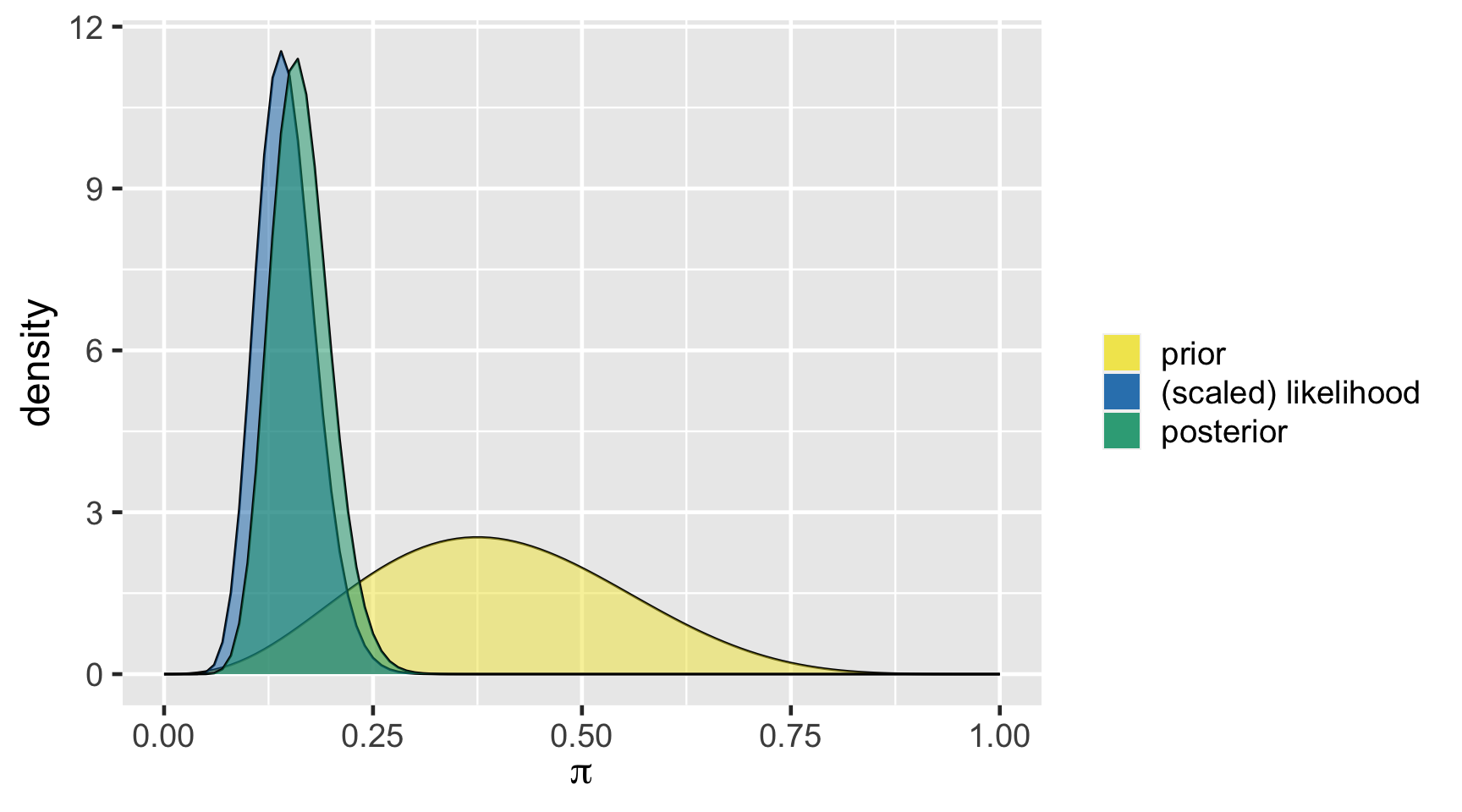
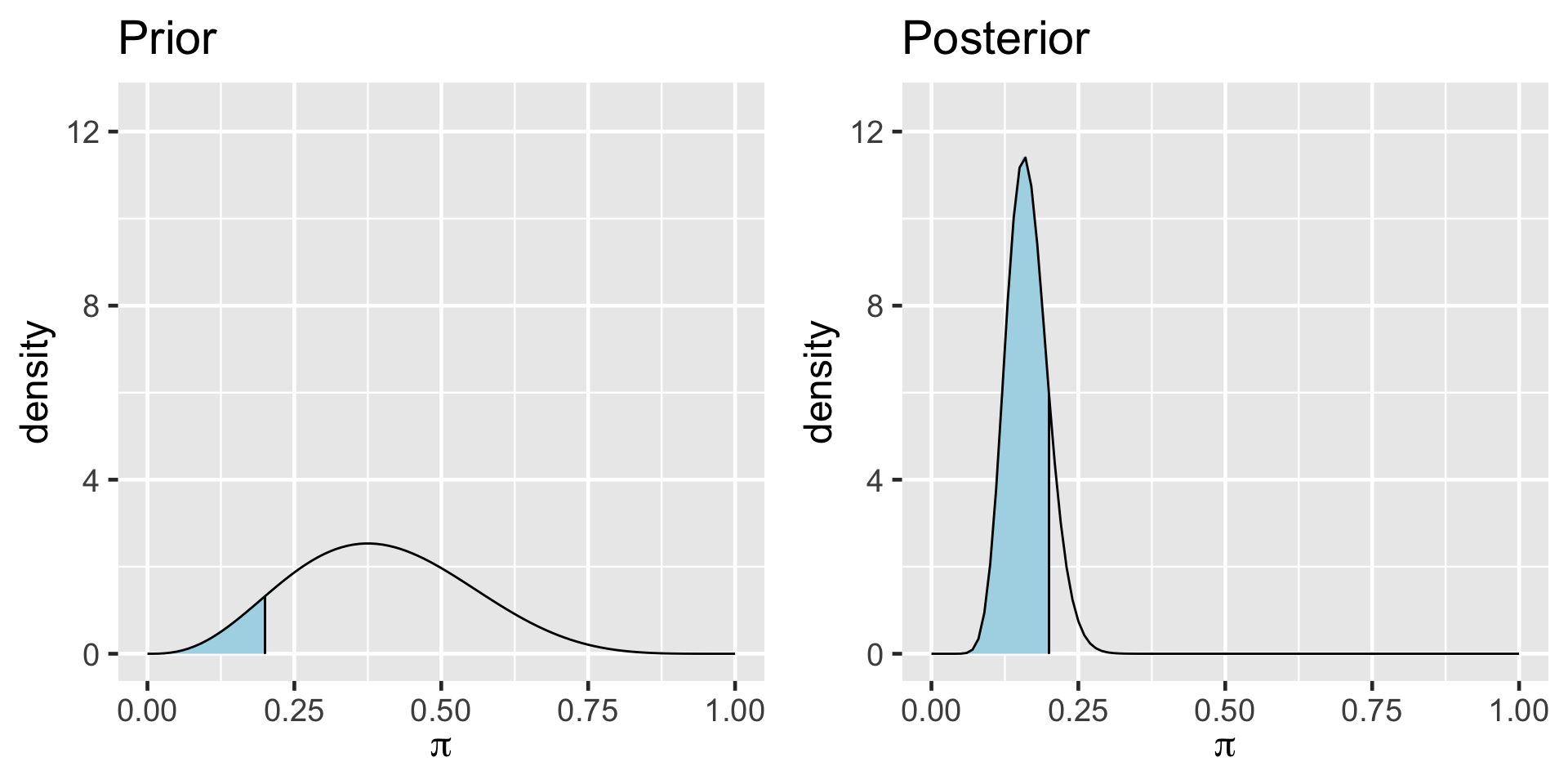
TRUE 16921 0.84605a Bayesian analysis assesses the uncertainty regarding an unknown parameter \(\pi\) in light of observed data \(Y\).
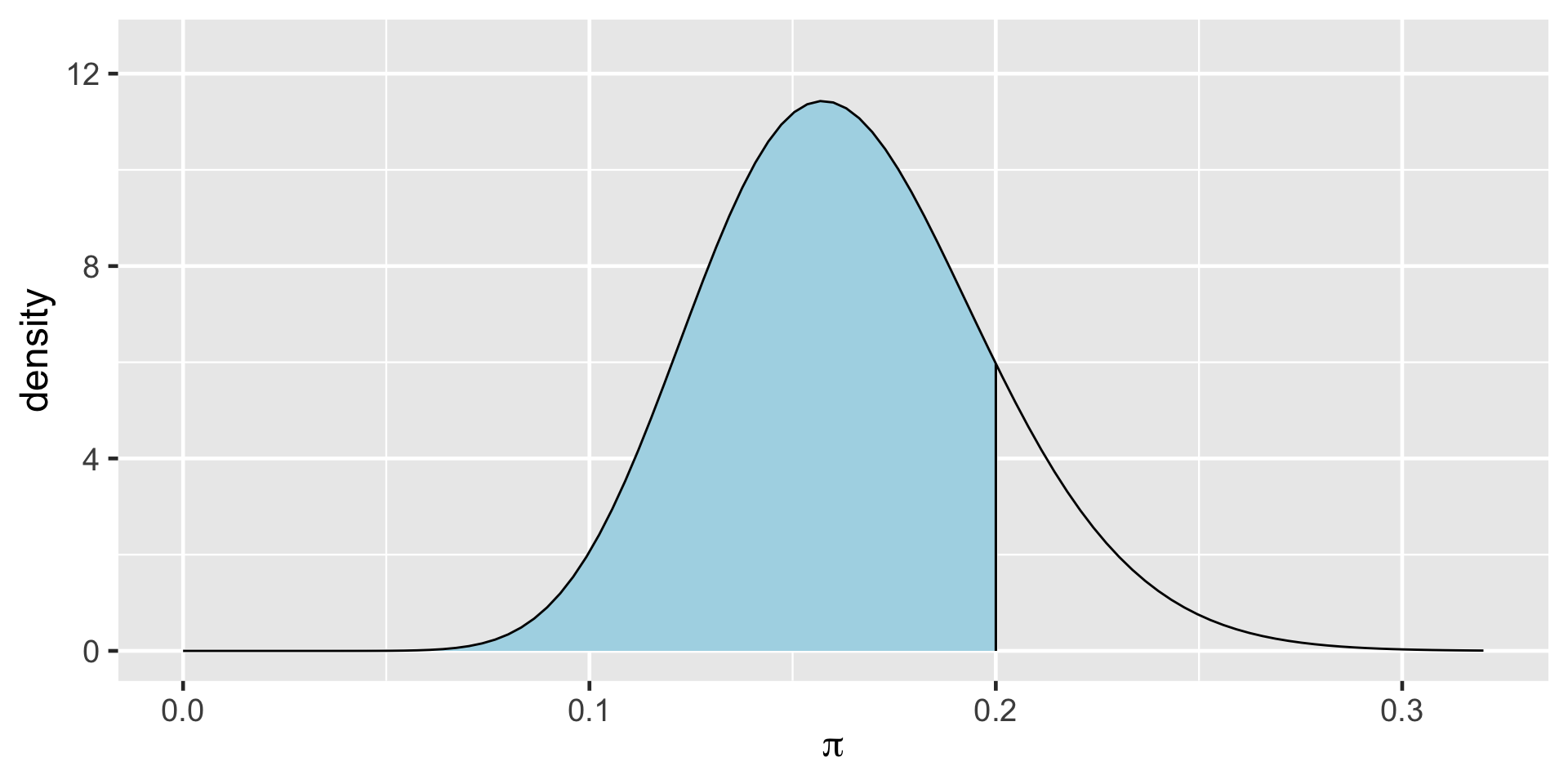
\[P((\pi < 0.20) \; | \; (Y = 14)) = 0.8489856 \;.\]
a frequentist analysis assesses the uncertainty of the observed data \(Y\) in light of assumed values of \(\pi\).
\[P((Y \le 14) | (\pi = 0.20)) = 0.08\]
![]()